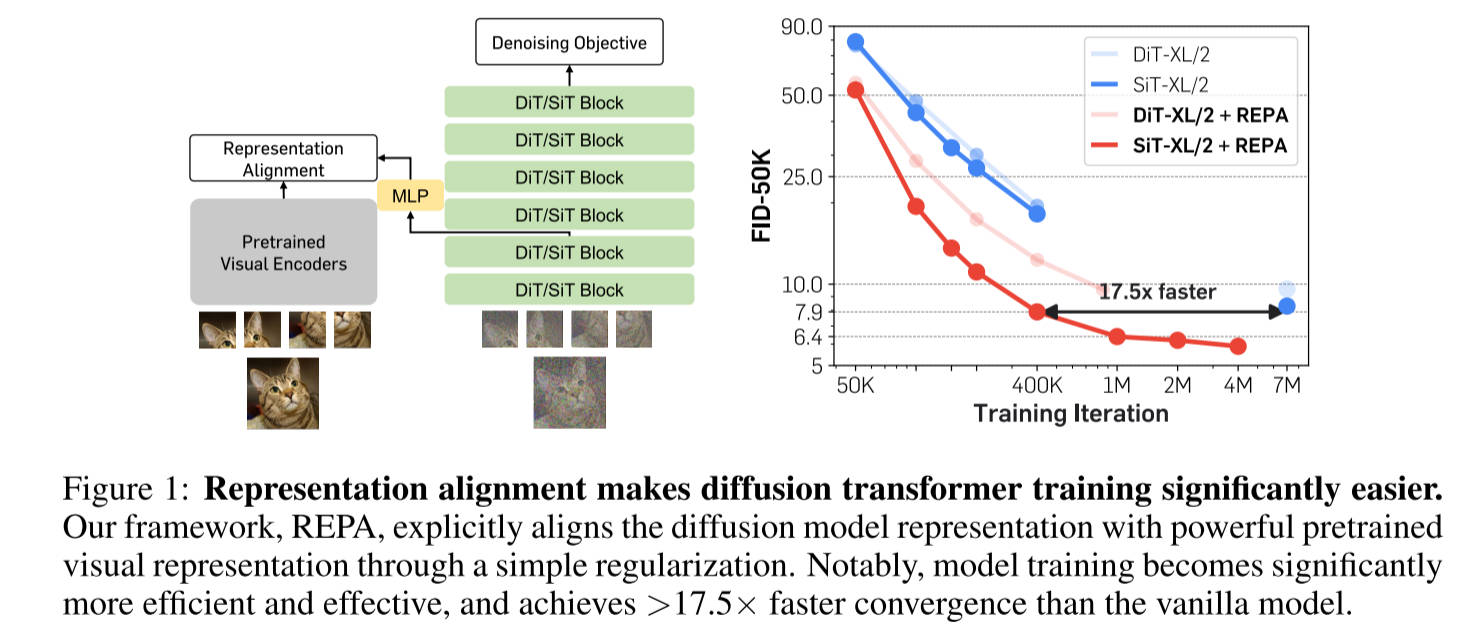
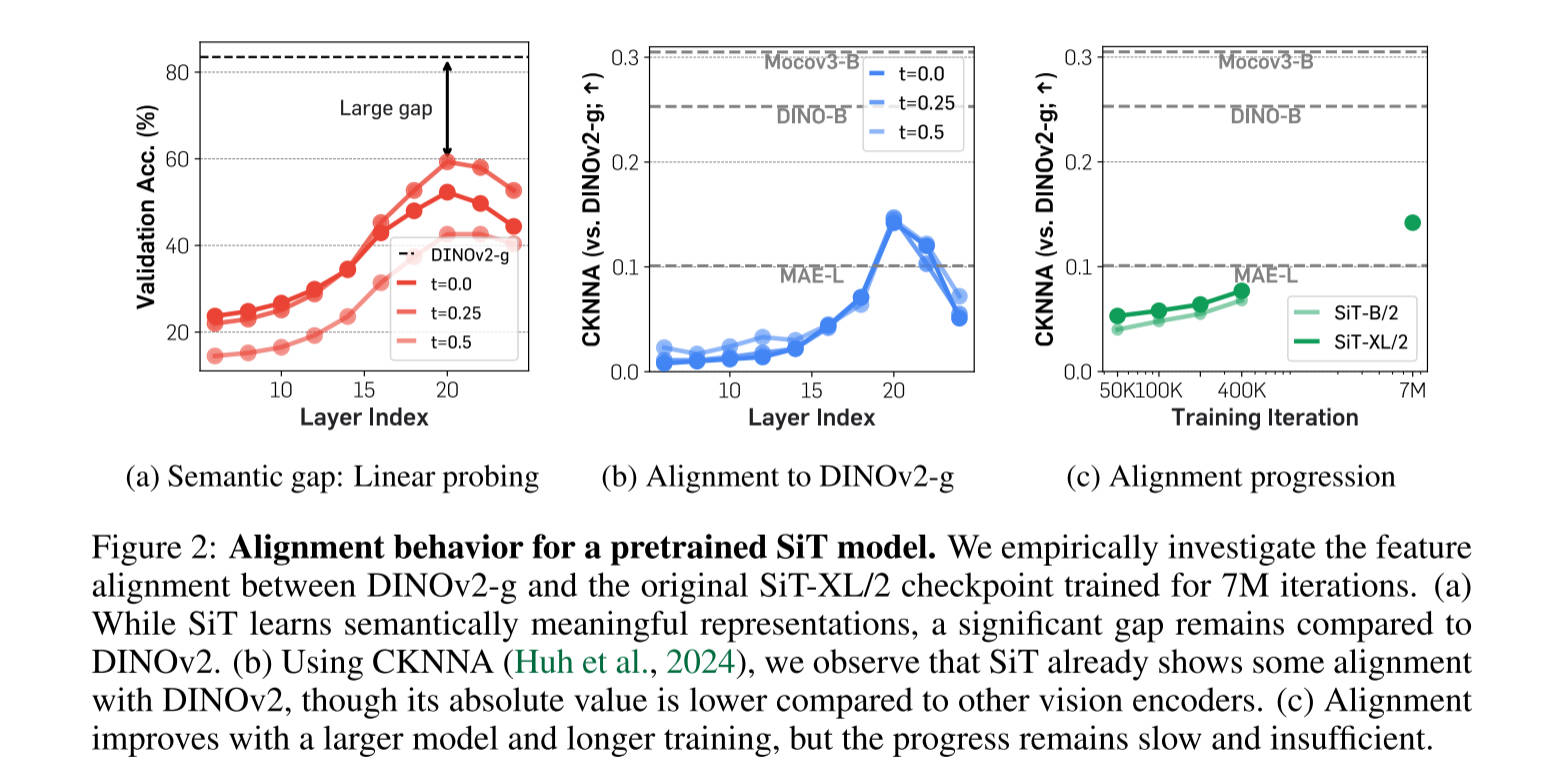
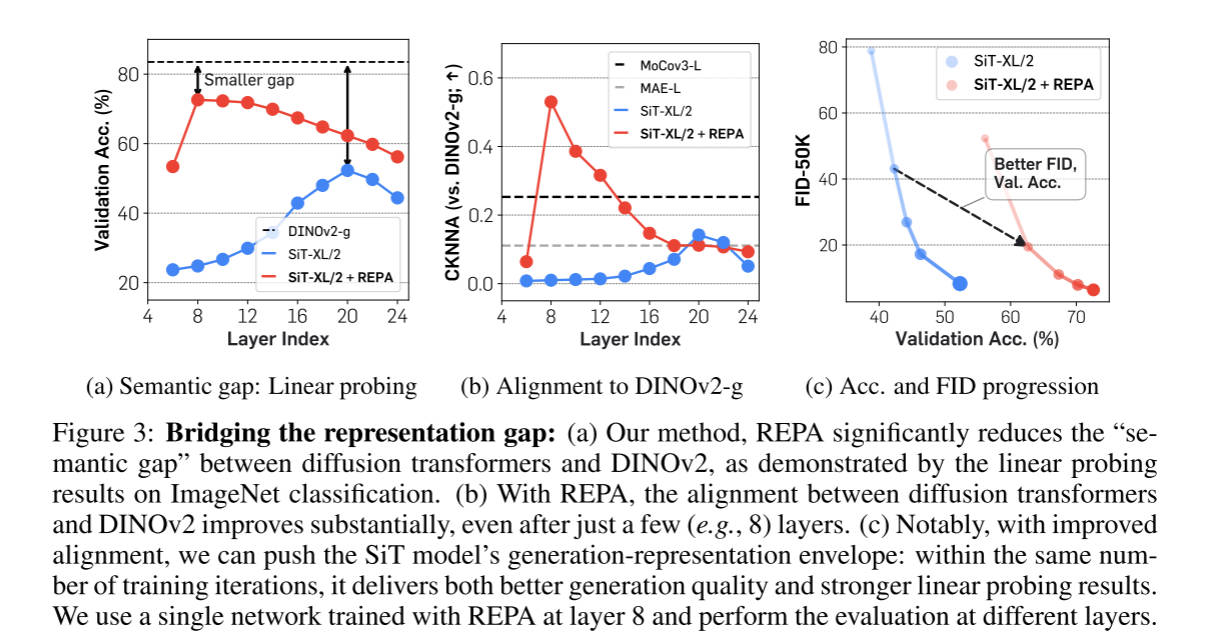
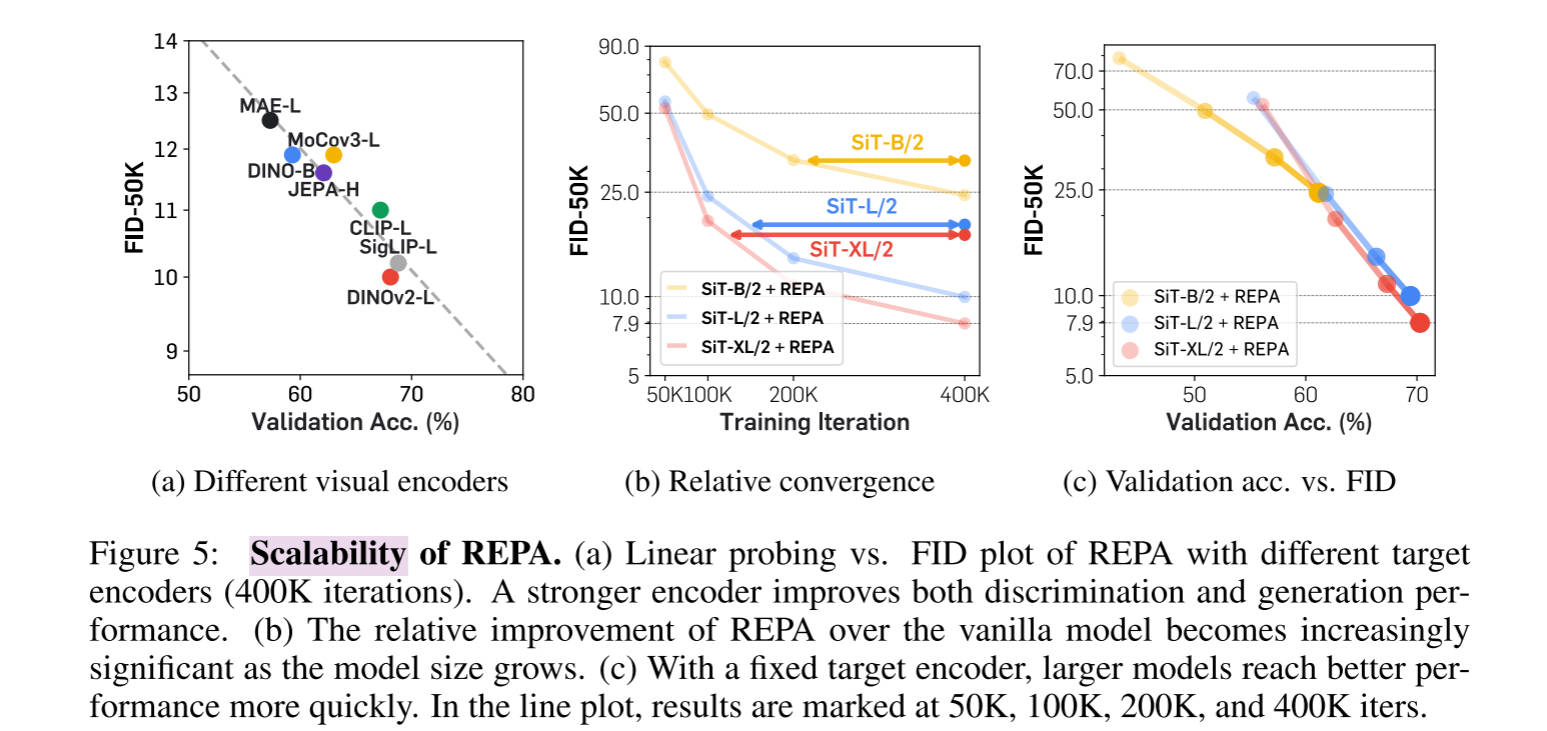
作者使用Linear Probing 和 CKNNA
来评估扩散模型的内部表征能力,图2a所示,作者观察到预训练扩散变压器的隐藏状态表示,在第20层实现了相当高的线性探测峰(t表示dropout
ratio used in linear
probing)。然而,它的性能仍然远远低于DINOv2,这表明两种表示之间存在很大的语义差距。此外,在达到这个峰值后,线性探测性能迅速下降,这表明扩散转换器必须从仅仅专注于学习语义丰富的表示转变为生成具有高频细节的图像。
在图2b中,作者使用CKNNA报告了SiT和DINOv2之间的代表性比对。特别是,SiT模型表示已经表现出比MAE更好的一致性。然而,绝对对齐得分仍然低于其他自监督学习方法(例如,MoCov3
vs.
DINOv2)。这些结果表明,虽然扩散变压器表示与自监督视觉表示表现出一定的一致性,但一致性仍然很弱。
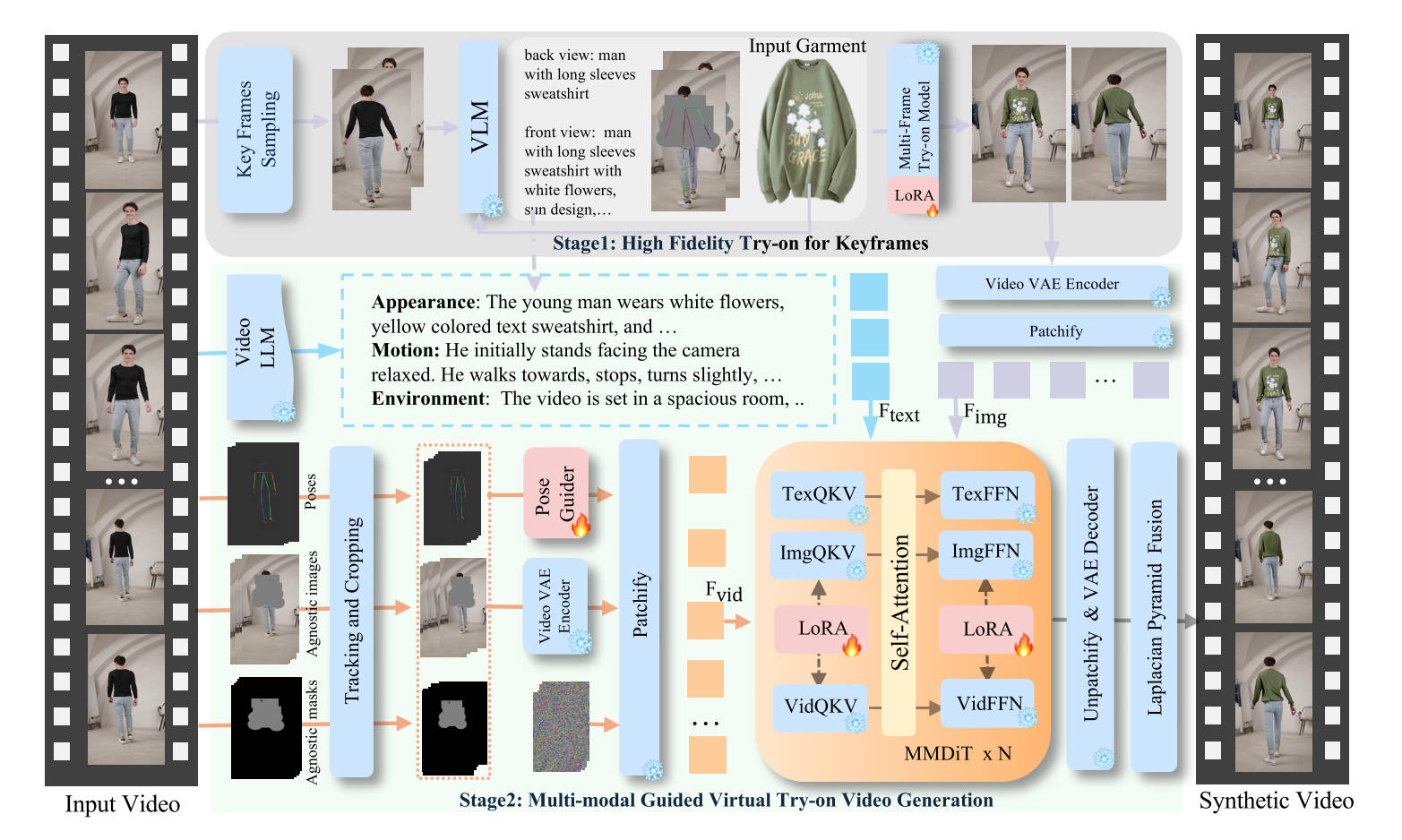
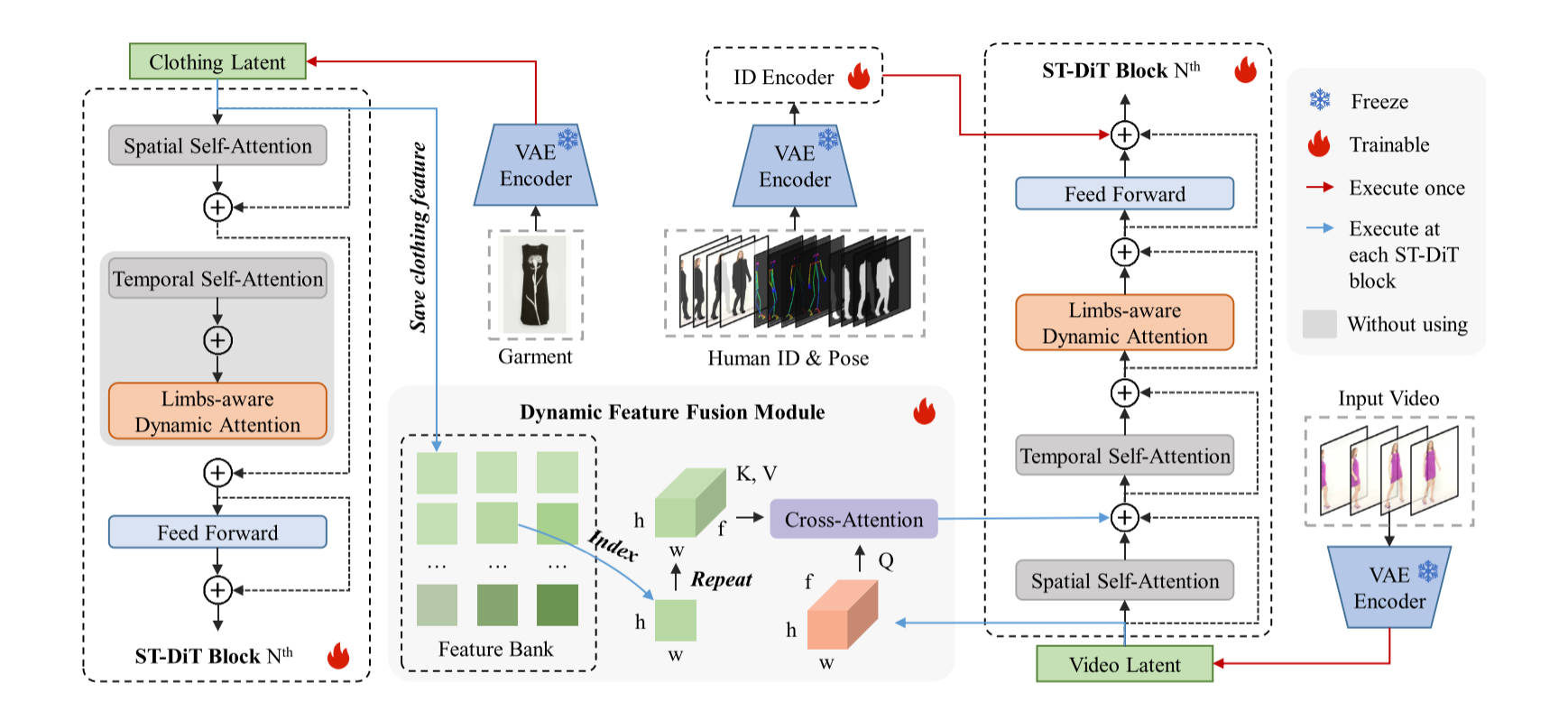
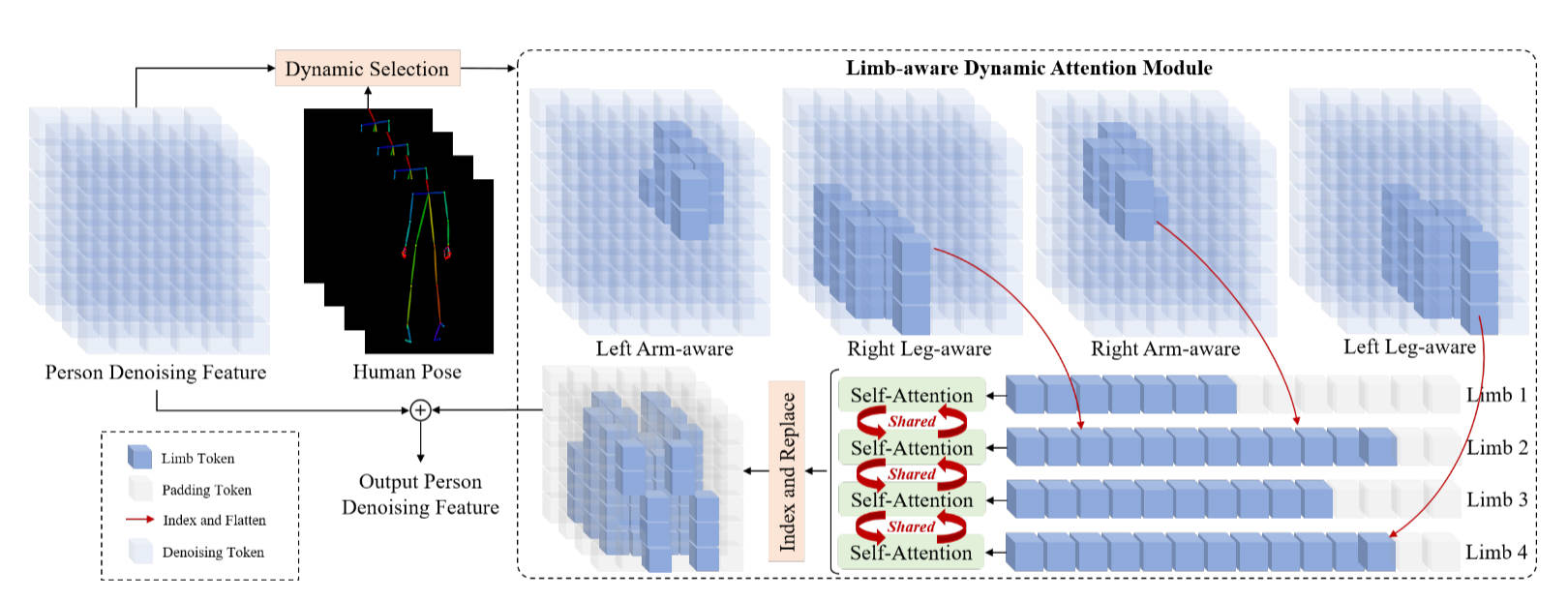
图1: DreamVVT can generate high-fidelity and temporally coherent virtual
try-on videos for diverse garments and in unconstrained scenarios.
Specifically, the first row shows its ability to handle complex human
motions like runway walks and 360-degree rotations;the second row
illustrates robustness to complex backgrounds and challenging camera
movements; the third row highlights visually coherent try-on results for
cartoon characters with real garments.
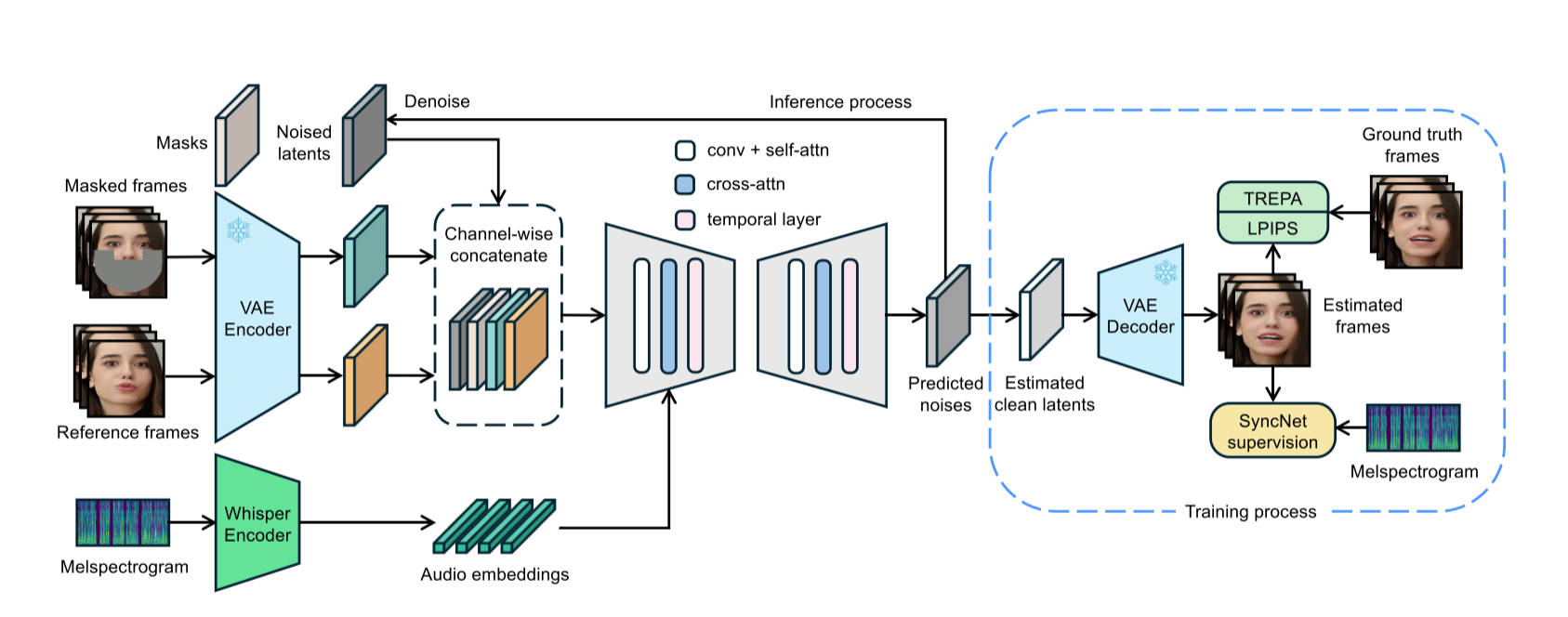
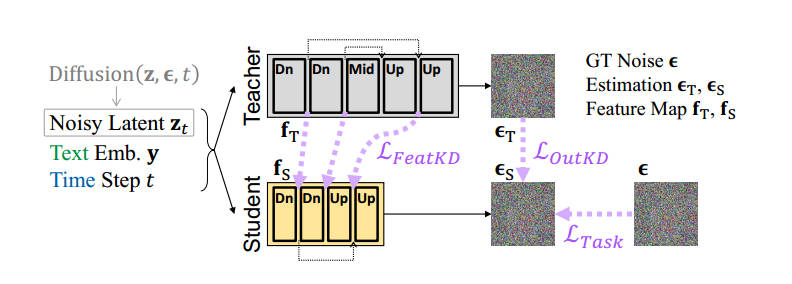
考虑到一半的损失只能改善生成图像的内容质量而并不关注时序一致性,作者使用自监督视频模型VideoMAE-v2提取时序表征。设
\(\mathcal{T}\)
是一个自监督视频模型编码器(self-supervised video encoder),其输出为在
projection head 之前的嵌入表示。TREPA 损失定义为:
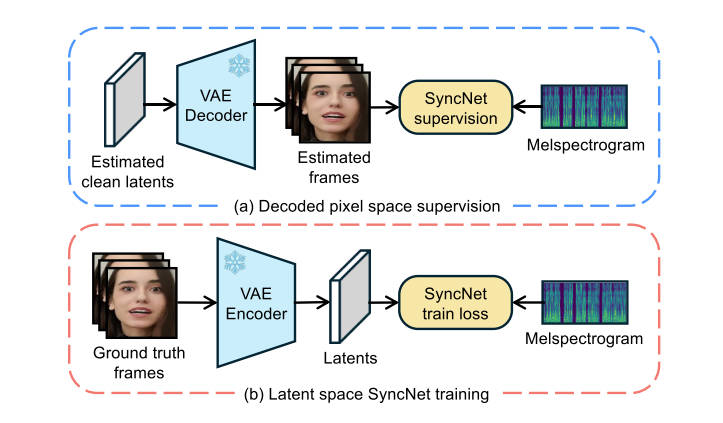
这个部分探索了为什么SyncNet训练不收敛的原因,在我看来更像是寻找合适超参数的过程。作者最终确定batch
size大小为1024,Embedding dimension为2048,number of
frames为16。除此之外,作者介绍了SyncNet的结构和数据处理的一些过程,在仓库中可以看到详细的数据处理管道。
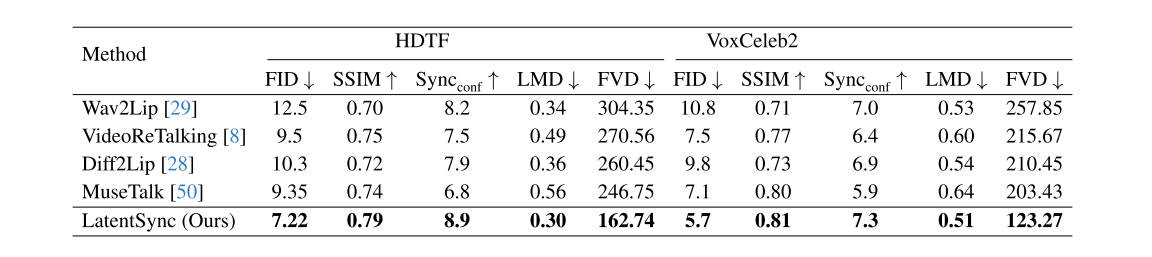
实验结果
表1: Quantitative comparisons on HDTF and VoxCeleb2.
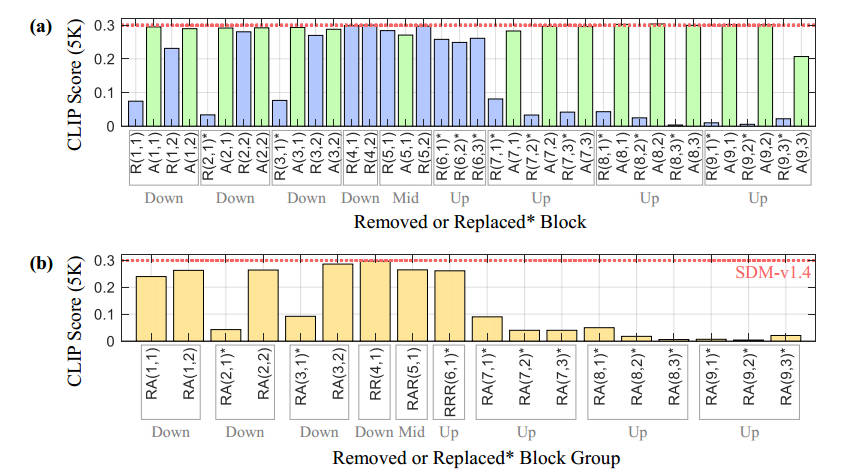
图2: Importance of (a) each block and (b) each group of paired/triplet
blocks.
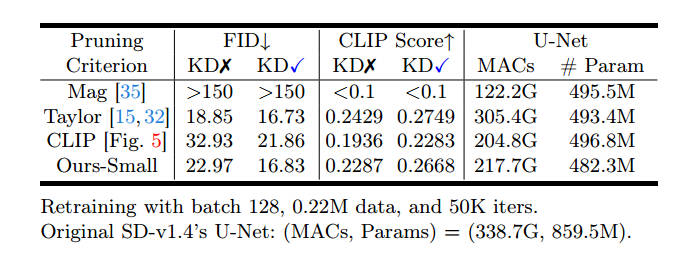
图3: Different block-level criteria at similar parameters. Taylor
pruning removes solely the inner blocks, leading to insufficient
reduction in MACs. Our method attains a favorable compromise between
performance an inference speed. Results on MS-COCO 30K.
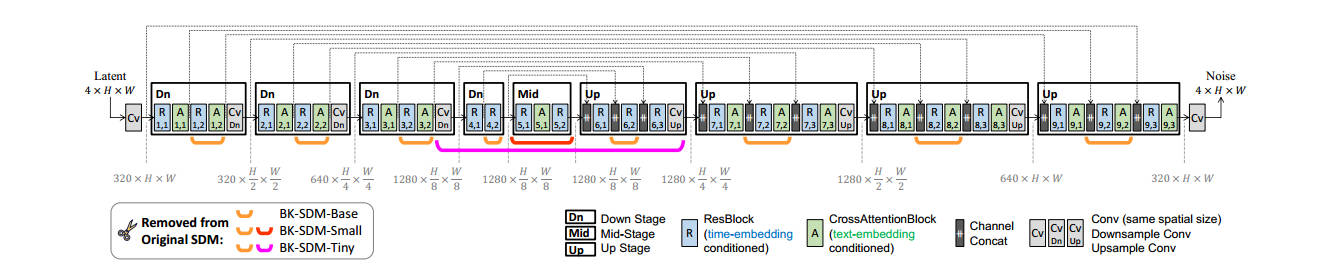
作者还发现删除中间块(Middle
Block)对于SD模型的性能影响是微小的,如图4所示。
图4: Minor impact of removing the midstage from the U-Net. Results
without retraining.
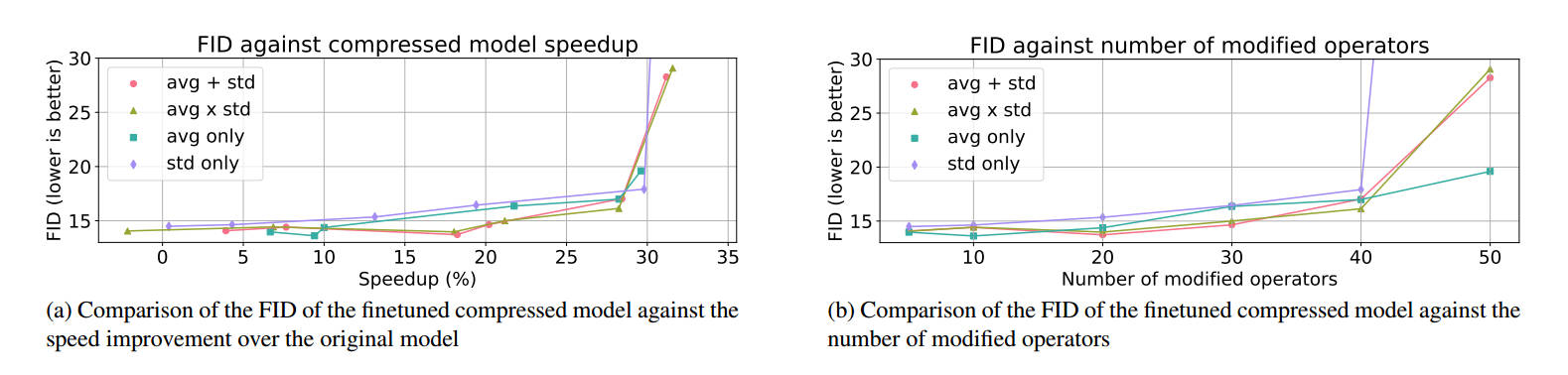
图3: Qualitative comparison of the impact of various combination methods
for average and standard deviation in our proposed scoring metric, with
SD. The results are without finetuning.
图4: Quantitative comparison of the impact of various combination
methods for average and standard deviation in our proposed scoring
metric, with UIG. The FID is measured after 20k iterations of
finetuning.
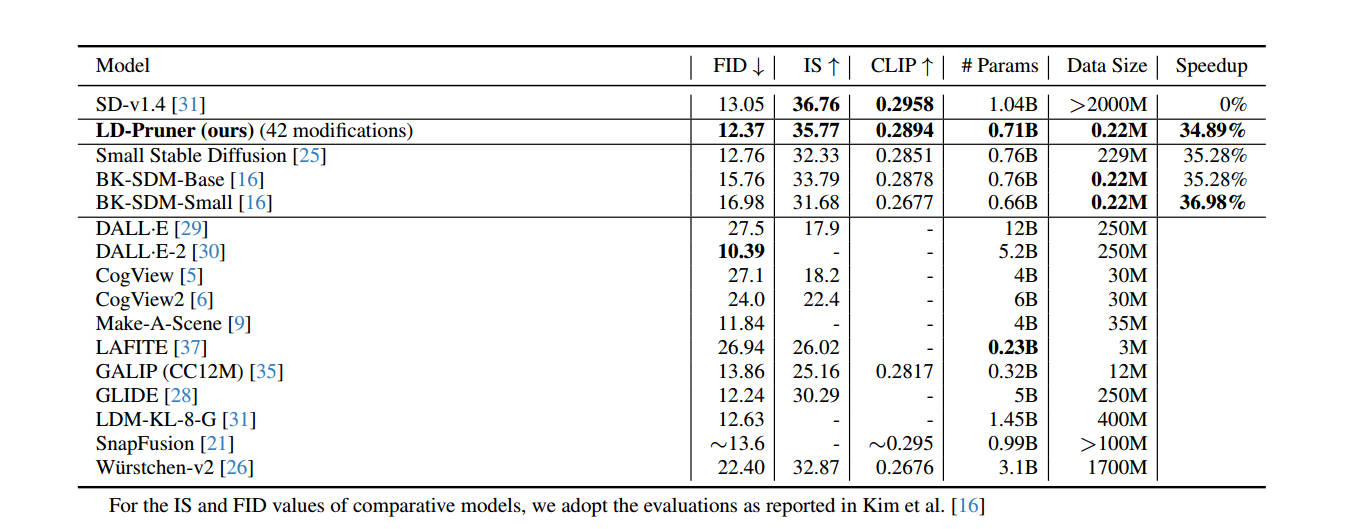
图6: Comparison of different models for T2I Generation, on the MS-COCO
256 × 256 validation set. Speedup values are measured relatively to
SD-v1.4.
图7: Qualitative comparison on zero-shot MS-COCO benchmark on T2I.
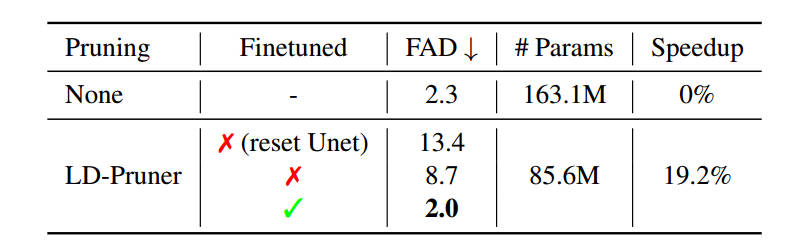
图8: Compression performance on UAG task with AudioDiffusion. When
finetuning, we proceed for 12k steps.
图8展示了在UAG上的实验结果,剪枝之后的模型微调后,在FAD上超越了基线模型。
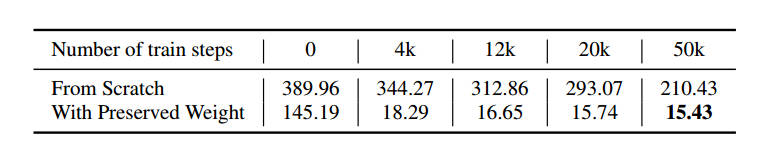
图9: FID scores for our compressed model (31 operators modified) trained
from scratch and with preserved pre-training weights, for UIG on
CelebA-HQ 256 × 256. In both case, the exact sametraining is applied.
The FID for the original model is 13.85.
类比:有一堆书,有 N 本,每本有 C 页,每页有 H 行,每行 W
个字符,而每个字符可以看成具有不同信息量或者复杂度的数值。BN
求均值时,相当于把这些书按页码一一对应地加起来(例如第1本书第36页,第2本书第36页......),再除以每个页码下的字符总数:N×H×W,因此可以把
BN 看成求“所有书对应页的平均字符信息量”的操作,求标准差时也是同理。
\[
\begin{equation}
y = f(\mathbf{g} \odot \hat{\mathbf{a}}+\mathbf{b})
\end{equation}
\]
类比:有一堆书,有 N 本,每本有 C 页,每页有 H 行,每行 W
个字符,而每个字符可以看成具有不同信息量或者复杂度的数值。LN
求均值时,相当于把每本书所有页的字符数相加(例如第1本书第36页,第2本书第40页......),再除以每本书的字符总数:C×H×W,因此可以把
LN 看成求“每本书的平均字符信息量”的操作,求标准差时也是同理。
类比:有一堆书,有 N 本,每本有 C 页,每页有 H 行,每行 W
个字符,而每个字符可以看成具有不同信息量或者复杂度的数值。IN
求均值时,相当于把每本书每一页的字符数单独统计(例如第1本书第36页,第2本书第40页......),再除以每页的字符总数:H×W,因此可以把
IN 看成求“每本书每页的平均字符信息量”的操作,求标准差时也是同理。
组归一化|Group Normalization
介于LN和IN之间,将通道数分组,主要目的是为了节约显存。
类比:有一堆书,有 N 本,每本有 C 页,每页有 H 行,每行 W
个字符,而每个字符可以看成具有不同信息量或者复杂度的数值。GN
求均值时,相当于把每本书分成很多小册子,每个小册子有很多页,对每个小册子的字符数求和,再除以每个册子的字符总数:(C/G)×H×W,因此可以把
GN 看成求“每个册子的平均字符信息量”的操作,求标准差时也是同理。
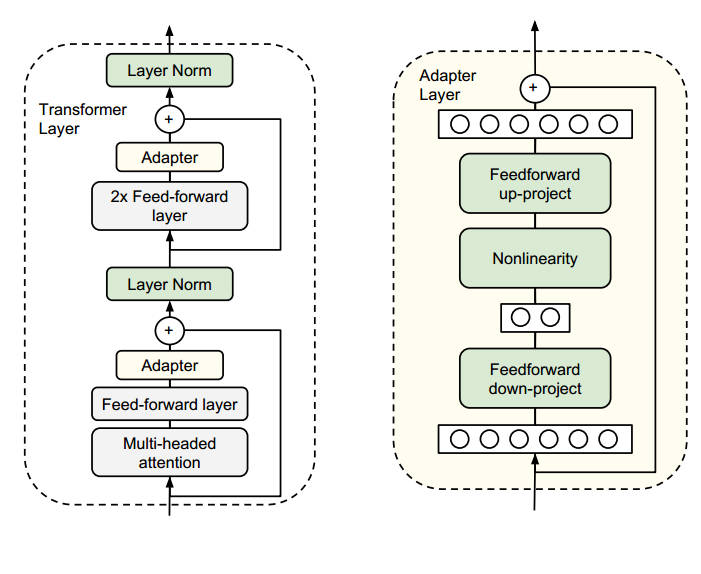
Adapter最初由论文“Parameter-Efficient Transfer Learning for
NLP”提出,策略是在Transformer的模型结构中在注意力层和前馈网络层之后加入两层全连接层和非线性激活函数,被称之为Adapter,第一层将d维向量映射到m维向量,第二层将m维向量映射回d维,以保持后续正确的残差连接,一个Adapter的总参数量为\((dm+m)+(md+d)\).如果你了解Transformer的实现,那么并不难知道Adapter加在哪里。
图1: Adapter
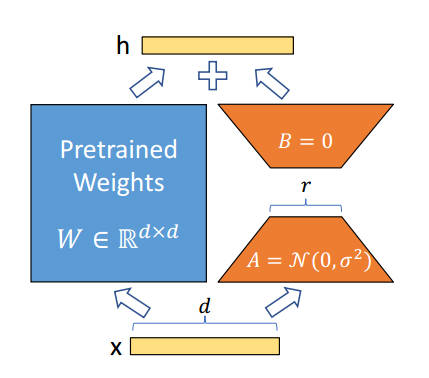
之后,借鉴Adapter的方法,论文“LORA: LOW-RANK ADAPTATION OF LARGE
LANGUAGE
MODELS”提出了LoRA低秩自适应微调技术。LoRA的策略是在Transformer的自主力层中,对q、v(注意力层中计算的三个向量分别是q、k、v)加入额外的类似于漏斗的全连接网络,与Adapter相似,第一个全连接层将维度缩小到r,第二个全连接层将维度恢复,之后将计算的q值与LORA相加。更精炼的概括是,LoRA在自注意力子层之间的q和v结果中添加了两个低秩矩阵进行微调。在研究中,LORA通常并不归类于Adapter中。
图2: Lora
提示微调(P-Tuning)
与P-Tuning相关的工作:
论文 “The Power of Scale for Parameter-Efficient Prompt
Tuning",Prompt Tuning的首创。
论文 ”Li and Liang, "Prefix-Tuning: Optimizing Continuous Prompts
for Generation",提出前缀调整Prefix-Tuning。
论文“P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning
Universally Across Scales and Tasks”在二者之上改进提出了P-Tuning
v2。
self.in_size = kwargs['in_size'] # Dim of the random variable to model (PV, wind power, etc) self.cond_in = kwargs['cond_in'] # Dim of context (weather forecasts, etc) self.latent_s = kwargs['latent_s'] # Dim of the latent space self.lambda_gp = kwargs['lambda_gp']
# Set GPU if available if kwargs['gpu']: self.device = torch.device("cuda:0"if torch.cuda.is_available() else"cpu") else: self.device = 'cpu'
# Build the discriminator alpha = 0.01 self.dis_net = [] for l1, l2 inzip(l_dis_net[:-1], l_dis_net[1:]): self.dis_net += [nn.Linear(l1, l2), nn.LeakyReLU(alpha)] self.dis_net.pop() # The last activation function is a ReLU to return a positive number self.dis_net.append(nn.ReLU()) self.dis = nn.Sequential(*self.dis_net)
# Discriminator's answers to generated and true samples D_true = self.dis(torch.cat((true_samples, context), dim=1)) D_generated = self.dis(torch.cat((generated_samples, context), dim=1)) # Compute Discriminator's loss with a gradient penalty to force Lipschitz condition gp = self.grad_pen(real=true_samples, samples=generated_samples, context=context) loss = -(torch.mean(D_true) - torch.mean(D_generated)) + self.lambda_gp * gp
super(Generator_linear, self).__init__() self.in_size = kwargs['in_size'] # Dim of the random variable to model (PV, wind power, etc) self.cond_in = kwargs['cond_in'] # Dim of context (weather forecasts, etc) self.latent_s = kwargs['latent_s'] # Dim of the latent space
# Set GPU if available if kwargs['gpu']: self.device = torch.device("cuda:0"if torch.cuda.is_available() else"cpu") else: self.device = 'cpu'
# Build the generator self.gen_net = [] for l1, l2 inzip(l_gen_net[:-1], l_gen_net[1:]): self.gen_net += [nn.Linear(l1, l2), nn.ReLU()] self.gen_net.pop() # Regression problem, no activation function at the last layer self.gen = nn.Sequential(*self.gen_net)