论文笔记|BK-SDM:A Lightweight, Fast, and Cheap Versionof Stable Diffusion
稳定扩散模型通常由数十亿个参数组成,文本生成图像任务中在生成高质量图像时需要很高的计算要求。为了提高效率,最近的研究包括剪枝、蒸馏、量化的相关工作致力于此。BK-SDM证明了在稳定扩散模型上剪枝再蒸馏训练的巨大潜力。在蒸馏训练中,第一次在特征和输出水平上构建蒸馏损失函数进行训练,用更少的资源和成本训练出具有竞争力的T2I模型,且更易部署在边缘设备上。
手工剪枝
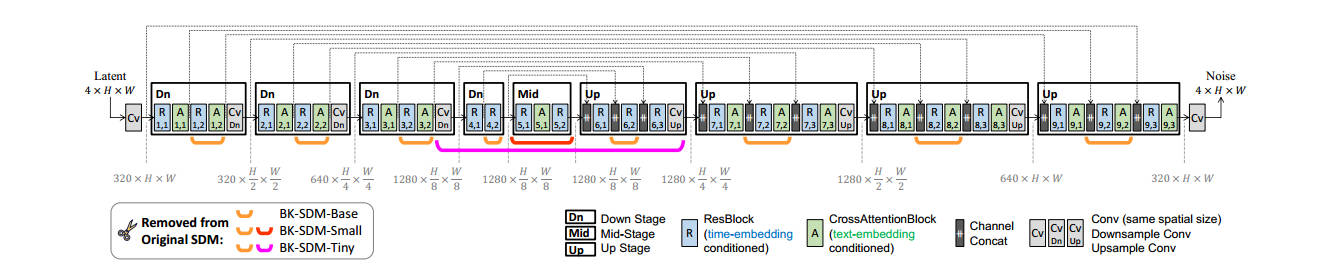
BK-SDM通过经验手动设计了三种型号的剪枝后SDM。具体结构如图1所示。
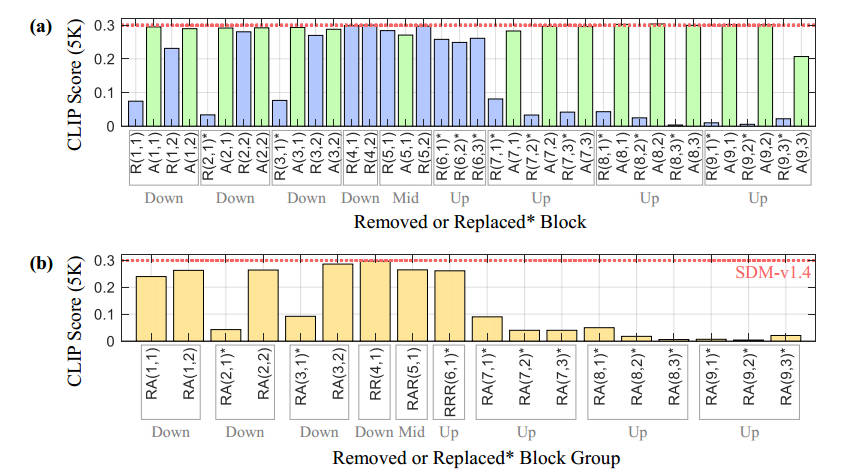
在图2的相关性分析中,作者认为CLIP分数无法正确反映层重要性,(a)中删除较多的Attn层而CLIP分数并没有显著下降,CLIP评分修剪敏感性的重要性标准会导致注意力块的过度修剪,最终结果不如手工设计的剪枝网络性能,结果对比展示在图3中。
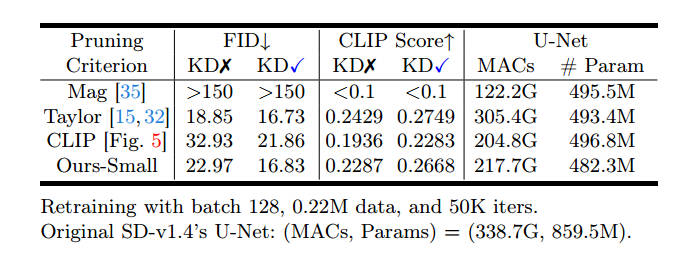
作者还发现删除中间块(Middle Block)对于SD模型的性能影响是微小的,如图4所示。

剪枝后蒸馏训练
为了恢复剪枝后模型的性能,BK-SDM采用蒸馏训练来对齐教师模型的输出。BK-SDM在feature-level和output-level上计算损失来训练学生模型。
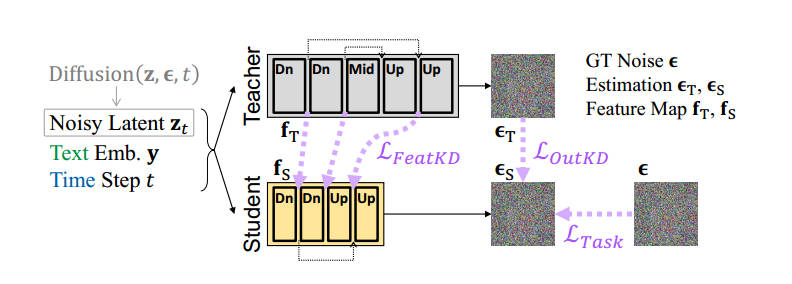
具体来说,损失函数由三部分组成,分别是任务损失,特征损失和输出损失:
\[ \begin{equation} L_{Task} = \mathbb{E}_{z,\epsilon,y,t}[||\epsilon - \epsilon_S(z_t, y, t)||_{2}^2] \end{equation} \]
\[ \begin{equation} L_{FeatKD} = \mathbb{E}_{z,\epsilon,y,t}[||\epsilon_T(z_t, y, t) - \epsilon_S(z_t, y, t)||_{2}^2] \end{equation} \]
\[ \begin{equation} L_{OutKD} = \mathbb{E}_{z,\epsilon,y,t}[\sum_{l} ||f_T^l(z_t, y, t) - f_S^l(z_t, y, t)||_{2}^2] \end{equation} \]
其中\(f_T^l(o)\)和\(f_S^l(o)\)分别代表预先定义的第l层的输出特征图。最终,损失公式如下:
\[ \begin{equation} L = L_{Task} + \lambda_{FeatKD} L_{FeatKD} + \lambda_{OutKD} L_{OutKD} \end{equation} \]
其中{FeatKD}和{OutKD}是可设置的超参数。