论文笔记|LD-Pruner:Efficient Pruning of Latent Diffusion Models using Task-Agnostic Insights
CVPR2024
潜在扩散模型(Latent Diffusion Models,LDMs)已经成为最强大的生成模型之一,其在有限计算资源的条件下展示了出众的结果。尽管如此,这些庞大的模型仍然难以在资源受限的环境下部署。LD-Pruner提出了一种严格的剪枝评估指标来对LDM进行结构化修剪。并在剪枝后使用知识蒸馏恢复模型性能,使其保持和教师模型同样的推理性能的同时大幅减少部署资源和推理时间。

一种新颖的评估指标
本文提出了一种全新的评估指标,旨在潜空间中(latent)对层重要性进行排序。假设\(L_{orig}\)和\(L_{mod}\)分别表示原始层集合和修剪后层集合,\(N_{gen}\)表示N次前向传播的输出潜在表示(latent representation)。定义第i次前向传播输出的潜在向量为\(l_{orig,i}\)和\(l_{mod,i}\)。
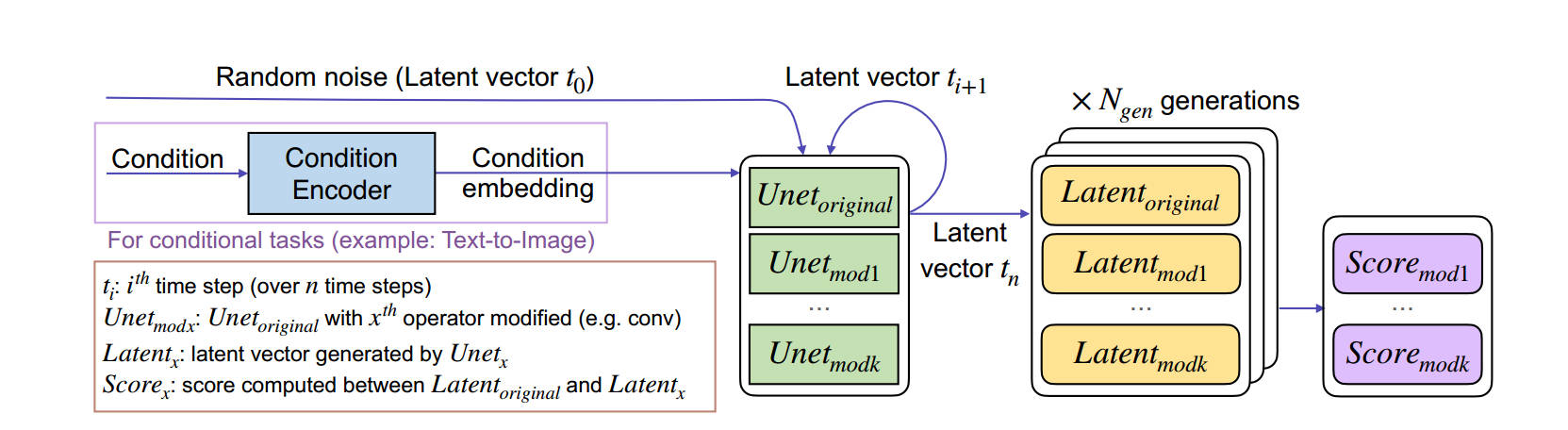
得分公式包括两部分:距离均值\(avg_{dist}\)和距离方差\(std_{dist}\)。
\[ \begin{equation} avg_{dist} = |avg_{orig}-avg_{mod}|_2 \\ std_{dist} = |std_{orig}-std_{mod}|_2 \end{equation} \]
其中 \(||_{2}\)表示欧几里得范数。
\[ \begin{equation} avg_{orig} = \frac{1}{N_{gen}} \sum_{i = 1}^{N_{gen}} l_{orig,i} \\ avg_{mod} = \frac{1}{N_{gen}} \sum_{i = 1}^{N_{gen}} l_{mod,i} \end{equation} \]
\[ \begin{equation} std_{orig} = \sqrt{\frac{1}{N_{gen}} \sum_{i = 1}^{N_{gen}} {avg_{orig} - l_{orig,i}}^2} \\ std_{mod} = \sqrt{\frac{1}{N_{gen}} \sum_{i = 1}^{N_{gen}} {avg_{mod} - l_{mod,i}}^2} \end{equation} \]
最终,定义修改后模型的得分公式(scoring formula):
\[ \begin{equation} score = avg_{dist} + std_{dist} \end{equation} \]
也许你会问为什么是均值和方差相加,而不是单独用均值或方差,或者二者相乘。实际上,如何组合以及用哪种方式,是要有前置实验做相关性分析。

如图3所示,作者在定性比较中发现,具有较小均值的层,文章里称之为operator(算子)延迟了图像退化为噪声的时间,即删除带来的损害更小;而较小的方差意味着可以保留更多的图像细节。
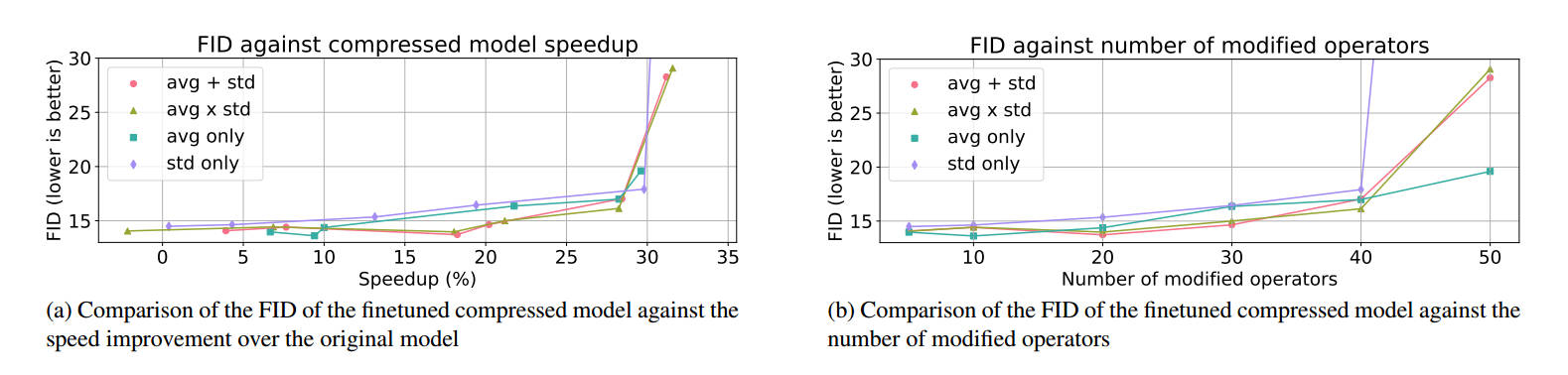
在定量实验中,在FID的比较中,相加略优于相乘,最终作者选用了相加作为得分公式。

LD-Pruner算法如上,其中k类似于剪枝率,表示要剪枝多少层网络。
剪枝后训练
通常剪枝都会伴随着模型的重新训练,本文中使用知识蒸馏(Knowledge Distillation, KD)训练剪枝后的模型。LD-Pruner沿用BK-SDM中提出的蒸馏方法,即在特征水平和输出水平上对齐教师模型。特征水平上,在每个stage(Up、Down、Middle)之后的结果进行对齐;输出水平上,是指最终模型的输出结果进行对齐。
实验
作者分别在文生图(T2I)、无条件图像生成(UIG)、无条件音频生成(UAG)任务上实现他们的方法,证明了LD-Pruner的有效性。
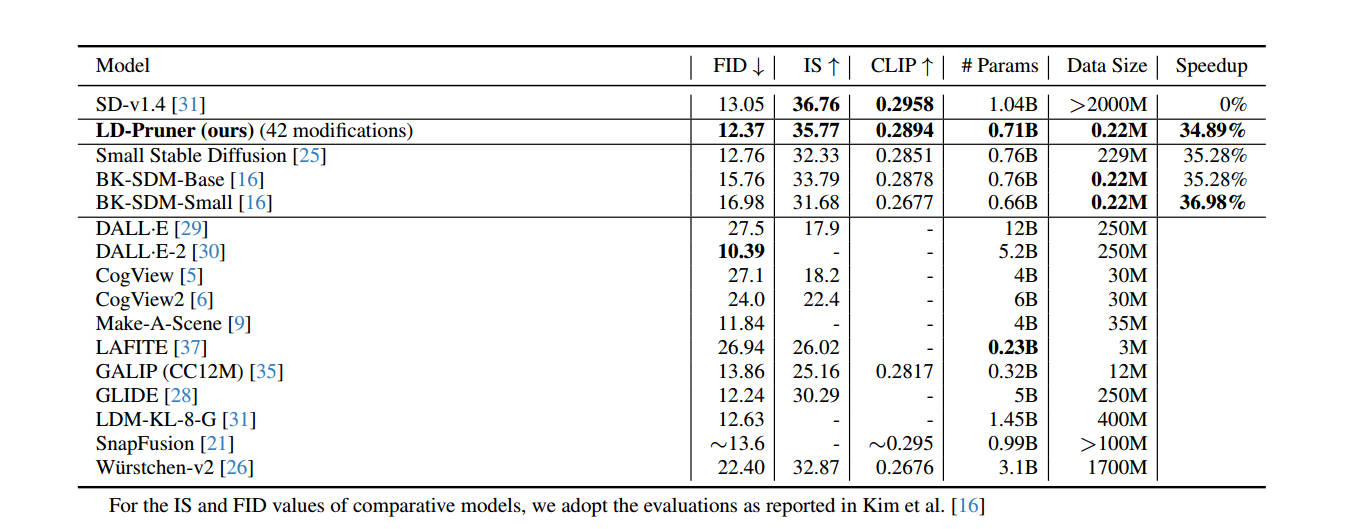

作者在MS-COCO数据集上详细展示了定性和定量的实验结果,T2I上剪枝后的模型FID上甚至超越了基线模型。
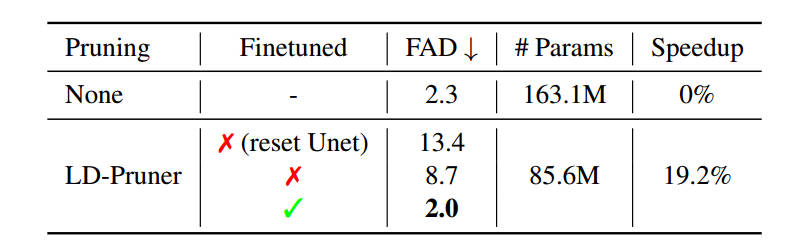
图8展示了在UAG上的实验结果,剪枝之后的模型微调后,在FAD上超越了基线模型。
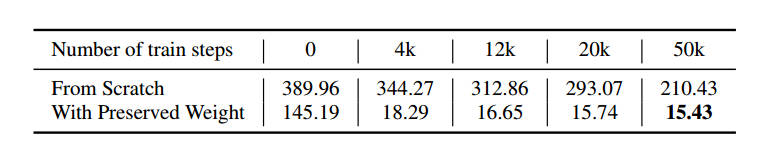
图9展示了UIG实验结果,对比了不加载预训练权重的模型,证明了剪枝后加载预训练权重的重要性,实验在CeleBA-HQ上进行。