即插即用(Plug and Play)|Efficient Fine-tuning Technology
学习笔记|大模型微调方法
最近在看一些模型微调的相关方法,阅读了不少论文,想做个小结,分享给需要的朋友。
直接微调
直接微调是指在不改变模型结构的基础上 ,加载预训练模型并在有限的数据集上微调训练,通常选取更小的学习率,通常的一些技术有全量微调,冻结部分参数等。
- 全量微调
全量微调是指每次更新模型的全部参数,这种方式在已有预训练权重的基础上进行,训练和预训练一样,但是由于预训练模型已经学习到了一定的先验知识,所以会降低微调的训练成本,模型可以更快地收敛。
- 部分微调(冻结)
部分微调是指冻结模型的一部分层的参数不参与梯度更新的过程,这种方式在某些情况下被证明具有比全量微调更大的优势。除了简单的冻结层之外,不同的论文提出了不同的冻结策略,比如只微调偏置bias,或者只对归一化层等进行调整。
适应性微调(Adapter)
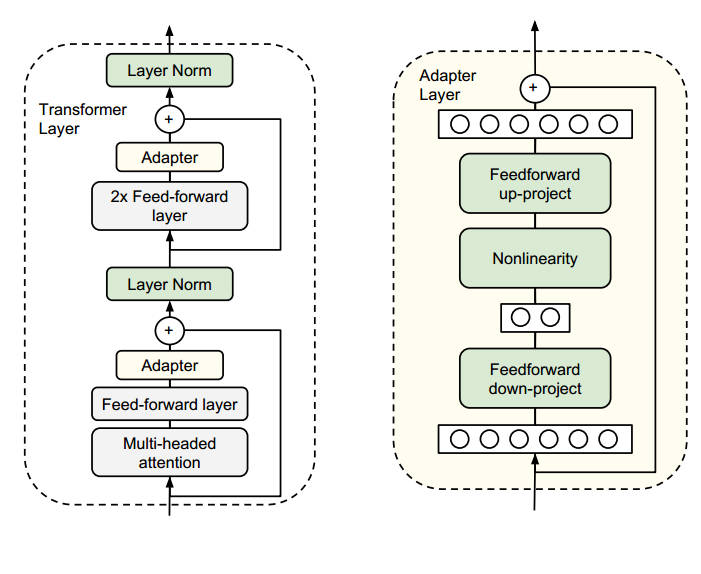
Adapter最初由论文“Parameter-Efficient Transfer Learning for NLP”提出,策略是在Transformer的模型结构中在注意力层和前馈网络层之后加入两层全连接层和非线性激活函数,被称之为Adapter,第一层将d维向量映射到m维向量,第二层将m维向量映射回d维,以保持后续正确的残差连接,一个Adapter的总参数量为\((dm+m)+(md+d)\).如果你了解Transformer的实现,那么并不难知道Adapter加在哪里。
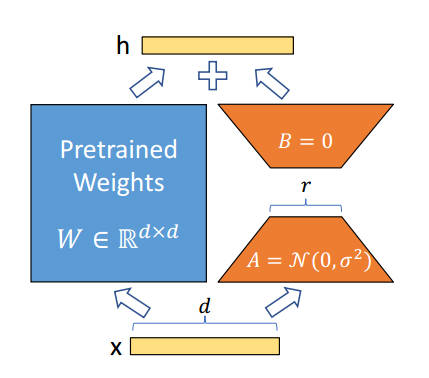
之后,借鉴Adapter的方法,论文“LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS”提出了LoRA低秩自适应微调技术。LoRA的策略是在Transformer的自主力层中,对q、v(注意力层中计算的三个向量分别是q、k、v)加入额外的类似于漏斗的全连接网络,与Adapter相似,第一个全连接层将维度缩小到r,第二个全连接层将维度恢复,之后将计算的q值与LORA相加。更精炼的概括是,LoRA在自注意力子层之间的q和v结果中添加了两个低秩矩阵进行微调。在研究中,LORA通常并不归类于Adapter中。
提示微调(P-Tuning)
与P-Tuning相关的工作:
论文 “The Power of Scale for Parameter-Efficient Prompt Tuning",Prompt Tuning的首创。
论文 ”Li and Liang, "Prefix-Tuning: Optimizing Continuous Prompts for Generation",提出前缀调整Prefix-Tuning。
论文“P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks”在二者之上改进提出了P-Tuning v2。
以上是目前主流的三大类微调方法,每种类别下又有这各式各样不同的小设计,尽管很多方法最先出自NLP领域,但随着技术的不断发展,CV与NLP领域的交叉融合趋势不断演进,期待未来更多高效的微调方法的出现。