论文笔记|DreamVVT:Mastering Realistic Video Virtual Try-On in the Wild via a Stage-Wise Diffusion Transformer Framework
视频虚拟试穿(video virtual try-on,VVT)技术在电子商务、广告和娱乐等领域的应用前景广阔,引起了学术界的广泛关注。然而,大多数现有的端到端方法严重依赖于稀缺的以服装为中心的成对数据集,无法有效地利用先进视觉模型的先验性和测试-时间输入(test-time inputs)。使得在不受约束的场景中准确保存细粒度的服装细节和保持时间一致性具有挑战性。为了应对这些挑战,我们提出了DreamVVT,这是一个精心设计的两阶段框架,建立在扩散变压器(dit)之上,它本质上能够利用各种不成对的以人为中心的数据来增强现实世界场景的适应性。为了进一步利用来自预训练模型和测试时间输入的先验知识,在第一阶段,我们从输入视频中采样代表性帧并利用结合视觉语言模型(VLM)的多帧试戴模型,进一步合成高保真和语义一致的关键帧试穿图像。这些图像作为后续视频生成的补充外观指导。在第二阶段,从输入内容中提取骨架映射以及细粒度的运动和外观描述,然后将这些与关键帧试镜图像一起输入到使用LoRA适配器增强的预训练视频生成模型中。这确保了看不见的区域的长期时间一致性,并使高度可信的动态运动成为可能。大量的定量和定性实验表明,DreamVVT在真实场景中保留服装的详细信息和时间稳定性方面优于现有的方法。

现有的问题
现有的方法难以准确地保留细粒度的服装细节,并在不受约束的场景中保持时间一致性,例如复杂的主体或摄像机运动、动态场景和不同的角色风格。我们认为,这些限制主要源于对端到端训练范式的依赖,而这固有地限制了对不成对数据、先进视觉模型先验和推理阶段附加信息的有效利用。
首先,这些方法所严重依赖的配对的服装视频数据不足,其中大多数是在均匀的室内环境中收集的。这通常会导致服装视觉保真度降低和时间不稳定性增加,特别是对于任意服装和复杂的视频输入。此外,在不同的现实世界场景中收集大规模成对的服装视频数据集仍然极具挑战性。
其次,这些方法采用预训练的文本到视频生成模型,将空间错位的服装图像逐帧变形到人身上。然而,这种方法破坏了预训练模型平滑时空建模的固有能力,使模型收敛更具挑战性。此外,在预训练的模型中对所有参数进行完全微调时,由于数据量有限,容易破坏预训练的先验,这反过来又降低了生成视频的质量和时间稳定性。即使在大规模数据集和各种视频任务上训练了很大一部分模型参数,统一的视频创建和编辑方法仍然难以准确地保留服装细节并保持时间一致性,这主要是由于缺乏针对虚拟试穿的任务特定设计。
第三,在推理阶段,仅提供服装的正面图像来指导虚拟试穿过程,往往会导致当人转身或摄像机视点(camera viewpoint)发生重大变化时,不可见区域的结果不可信。
为了解决这些问题,作者引入了DreamVVT,这是一种基于扩散转换器(Diffusion transformer, dit)的改进的阶段式框架,它本质上能够利用来自不同来源的不成对的以人为中心的数据来提高现实场景中的泛化。为了进一步利用预训练模型和推理过程中的先验信息,
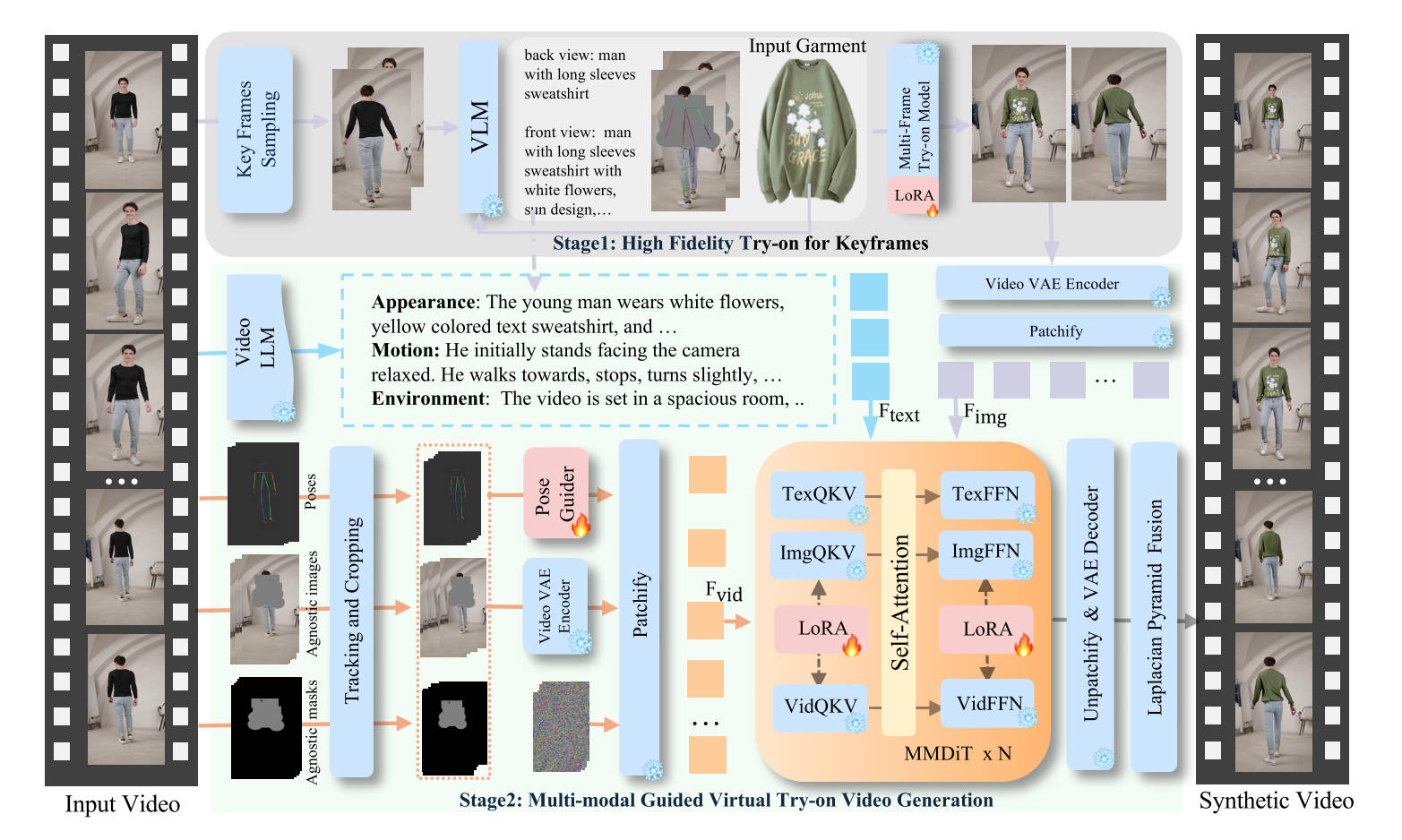
在第一阶段,作者首先从输入视频中采样具有显著运动变化的关键帧,然后使用视觉语言模型(VLM)生成文本描述,将输入服装映射到每个关键帧。将这些描述以及服装图像和其他相关条件提供给配备LoRA适配器的多帧试穿模型,从而获得每个关键帧的高保真度和语义一致的试穿图像。这些图像作为后续视频生成的补充外观指导。
在第二阶段,作者采用时间平滑姿态引导器(pose guider)进行骨骼特征编码,并利用先进的视频大语言模型(video LLM)从输入内容中提取细粒度的动作描述和其他高级视觉信息。这些特征以及空间对齐的关键帧试镜图像随后作为输入提供给使用LoRA适配器增强的预训练视频生成模型。通过利用大规模视频生成模型的预训练先验,该模型在野外场景中具有增强的泛化能力。此外,结合多个关键帧试穿图像和精确的运动指导,可以生成长期的(long-term)虚拟试穿视频,表现出强烈的时间一致性和高度可信的动态运动。此外,还引入了多任务学习策略来保持不同模态条件的可控性。
DreamVVT
DreamVVT采用了一种基于大型(large-scale)扩散变压器的分阶段框架,实现了无约束场景下的高保真虚拟试穿视频生成。如图2所示,它由两个连续的阶段组成。 在第一阶段,从输入视频中抽取具有显著运动变化的帧作为关键帧,然后开发多帧试穿模型,在保持内容一致性和保留精细细节的同时将服装图像适配到这些关键帧。 在第二阶段,我们提出了一种改进的视频生成模型,该模型综合了基于关键帧试穿图像、姿态特征和文本描述的可信(plausible)试穿视频。
输入条件
Pose Conditions
为了实现真实人物和卡通人物的虚拟试穿,作者采用RTMPose作为鲁棒的和高效的姿态表示。考虑到原始视频中的角色可能只占据有限的空间区域,直接将其原始分辨率的姿势序列输入到试衣模型中可能会导致生成视频中显著的服装细节丢失,这主要是由于空间降采样。为了解决这个问题,作者首先使用统一宽度和高度的跟踪边界框裁剪每一帧,从而隔离每一帧中的人物主体所在区域(character region)。
Agnostic Masks
以往的方法大多是通过直接扩大视频中分割的服装区域来生成agnostic mask,这很容易导致原始服装风格线索的泄露。为了缓解这个问题,作者使用人体边界框和扩展的姿势骨架来生成与服装无关的掩码(clothing-agnostic mask),有效地防止信息泄漏,同时尽可能多地保留原始背景。
Agnostic Images
通过应用agnostic masks,遮挡输入人物主体视频或图像中的服装区域,从而生成agnostic images。
Garment Images
对于服装图像输入,作者首先使用显著性分割检测模型提取前景区域,然后用白色像素填充去除背景区域。为了进一步促进服装细节的保存,作者根据提取的分割计算一个紧密的边界框,然后裁剪感兴趣的区域。最后,裁剪后的图像在输入到网络之前被调整到一个特定的分辨率。
阶段1:关键帧的高保真试穿
作者选择具有显著运动变化的帧,为视频生成提供更全面的指导。最初,考虑到大多数输入的服装图像都是从正面角度捕获的,作者预先定义了一个A姿势(A-pose)的正面视图人物图像作为锚帧。 随后,作者通过测量每个视频帧和锚帧各自骨骼关节方向向量之间的余弦距离来计算它们之间的运动相似度。这种相似性进一步通过主体在整个框架中的面积比例来加权,从而产生最终分数。最后,根据帧的最终分数按降序排序,并在最小分数区间约束下进行逆序搜索,得到一组信息冗余最小的关键图像。
给定选定的关键帧,作者利用具有最小可学习参数集的扩散转换器 \(G*\),来自于预训练的Seedream模型 \(G\) (增加了lora),生成最终的多帧试戴结果。通过将注意力模块与可插拔的LoRA集成,作者修改了 \(G\) 中的每个 \(MMDiT\) 块,并引入了一个额外的参数共享网络分支来处理实现后的参考图像输入。值得注意的是,\(G∗\) 将多关键帧图像条件对与精心设计的一致图像指令一起作为输入,这澄清了不同的输入组件,并有助于指导模型合成理想的结果。具体而言,作者首先通过并行网络架构对每个条件输入进行标记,以对齐不同的模态,然后在注意过程中通过Q, K, V 的交换聚合关键帧的信息。该机制确保了每个条件输入和关键帧中间特征之间的鲁棒的信息交互,从而实现了具有一致细节的连贯多帧试穿结果。对于文本输入,作者使用字节内部的 Seed1.5-VL 进行详细描述,包括每个关键帧的服装类别、材料和图案。随后,引入文本对齐过程,要求VLM重写并收集所有文本结果,进一步增强关键帧描述的一致性。
阶段2:多模态引导虚拟试穿视频生成
虚拟视频试穿模型基于预训练的图像到视频生成框架,该框架采用堆叠顺序MMDiT块,每个块都集成了文本和视频流。为了准确地重建输入视频中的身体运动,作者提取了相应的二维骨架序列。裁剪后,具有时间关注的定制姿态引导器(pose guider)将逐帧骨架图转换为在每个时间帧上与潜空间噪声分辨率匹配的平滑姿势潜在向量。同样,将裁剪后的 agnostic images 输入视频 VAE 编码器以获得 agnostic latents,并将裁剪后的agnostic masks 调整为与 agnostic latents 相同的分辨率。然后,将 agnostic latents、调整大小的 agnostic masks、nosie latents 和 pose latents 沿着通道维度进行 concatenate,并 patchfy 为视频 tokens,记为 \(F_{vid} \in R^{l_v×c}\)(其中\(l_v = t × h × w\), \(t = T/4\), \(h = H/16\), \(w = W/16\), \(t, h, w\)为输入视频的形状)。由于姿势骨架(pose skeletons)只捕获粗粒度的身体运动,不能完全表示细粒度的服装交互,我们使用 Qwen2.5-VL 提取属性解纠缠文本描述(attribute-disentangled textual description)——包含详细运动描述和高级视觉信息(在推理过程中,与外观相关的描述被替换为与目标服装对应的描述)。这些文本描述随后被Qwen LLM 处理成 text tokens,记为 \(F_{text} \in R_{l_t×c_t}\)。对于 appearance branch,首先由视频VAE编码器对关键帧尝试图像逐帧处理,提取 image latents,然后将其转化为image tokens,表示为 \(F_{img} \in R^{l_i×c}\) (其中\(l_i = k × h × w\), k 为关键帧的数量)。为了保持模型的时空建模和快速粘附能力,作者冻结了文本流的参数。轻量级的LoRA适配器,只包含10%的可训练参数,被插入到直接从视频流复制的冻结视频流和图像流中,具有共享内存。随着视频和图像tokens的通道数的增加,视频和图像流的输入投影层被设置为可训练的。最后,所有这些标记集通过各自的 QKV投影层 进行处理,然后沿着 l 维进行连接。结果序列被输入到一个完整的自注意力机制模块中,该模块使模型能够自适应地将视觉内容与文本描述跨空间和时间维度对齐。在自注意力机制操作之后,通过索引将 joint tokens 解复用为text、image、video tokens,这些 tokens 随后由以下DiT块处理。在DiT主干内进行多次去噪迭代后,生成试穿视频 tokens,之后通过 Video VAE decoder被解码成视频序列。然后采用高效的拉普拉斯金字塔融合方法,将生成的试穿视频无缝地融合到原始视频的相应区域中。在训练过程中,作者引入了多任务学习策略,其中一个任务(例如,文本到视频,带文本的姿势和关键帧到视频)是基于预定义的 probabilistic schedule 随机选择的,以充分利用各种模式的互补优势。