论文笔记|Dynamic Try-On:Taming Video Virtual Try-on with Dynamic Attention Mechanism
视频虚拟试穿(video virtual try-on,VVT)技术在电子商务、广告和娱乐等领域的应用前景广阔,引起了学术界的广泛关注。之前关于视频尝试的研究主要集中在将产品服装图像转移到具有简单人体姿势的视频中,而在复杂动作方面表现不佳。为了更好地保存服装细节,这些方法配备了一个额外的服装编码器,导致更高的计算资源消耗。目前该领域核心挑战:(1)利用服装编码器的视频试戴功能,同时降低计算需求;(2)确保人体各部位合成的时间一致性,特别是在快速运动时。
本文提出了Dynamic Try-On,包含两个模块:
1)Dynamic Feature Fusion Module (DFFM)动态特征融合模块:通过DiT主干提取并存储整合服装特征,保存服装细节。
2)Limb-aware Dynamic Attention Module (LDAM)肢体感知动态注意模块以及用于保存人的姿势和身份的轻量级身份保存编码器(ID Encoder):有效地跨帧传递身体信息,并产生时间一致的视频。
模型结构
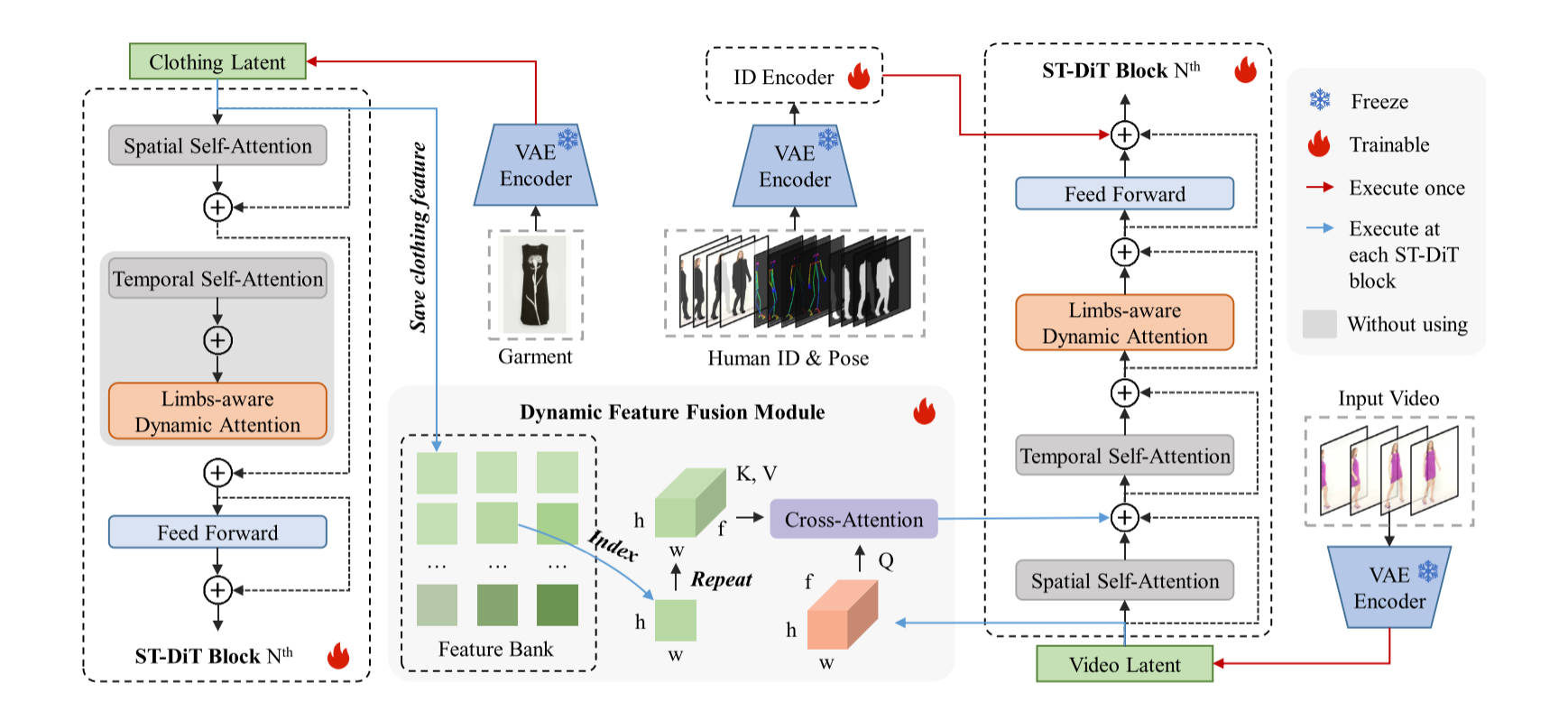
ID-Encoder
在虚拟试穿中,作者认为其可以视为一个修复问题(inpainting problem),提出了一个四元组 \({x_a, d_p, m_c, c}\),c代表目标服装将被应用于指定的人物视频\(x\), \(x_a\)代表衣服不可知的图像(cloth-agnostic image),\(d_p\)代表姿势骨架(pose skeleton),\(m_c\)代表要修复的掩码。在实现ID-Encoder时,作者采用类似ControlNet的方式,通过一个SiT-DiT块保存人物姿势、身份和背景信息。
Dynamic Attention Mechanism
动态注意力机制包括DFFM(动态特征融合模块)和LDAM(肢体感知动态注意模块)。从总体上看,网络先执行Garment的输入,经过一次前向计算得到特征图存储在Feature Bank中,之后网络进行第二次去噪前向传播,第二次前向传播包括了一个类似ControlNet的ID-Encoder模块来融合人物ID身份信息,在每个SiT-DiT块中,通过交叉注意力融合目标服装特征的信息,实现虚拟试穿。
DFFM
本质上,作者将SiT-DiT的去噪主干网进行共用,用来并行提取服装特征,如图1左边所示(灰色部分不参与服装特征提取过程),作者将每次经过SiT-DiT块之后的服装特征向量保存在一个Feature Bank中,这个过程需要一次完整的前向传播。之后,图1右边的去噪DiT-SiT主干网络进行去噪,在每次经过一个DiT-SiT块时,通过交叉注意力机制与Feature Bank中事先存好的服装特征进行融合,值得注意的是,左侧块与右侧块是对应的关系,Feature Bank中总共存储了N个特征图用于计算N次交叉注意。
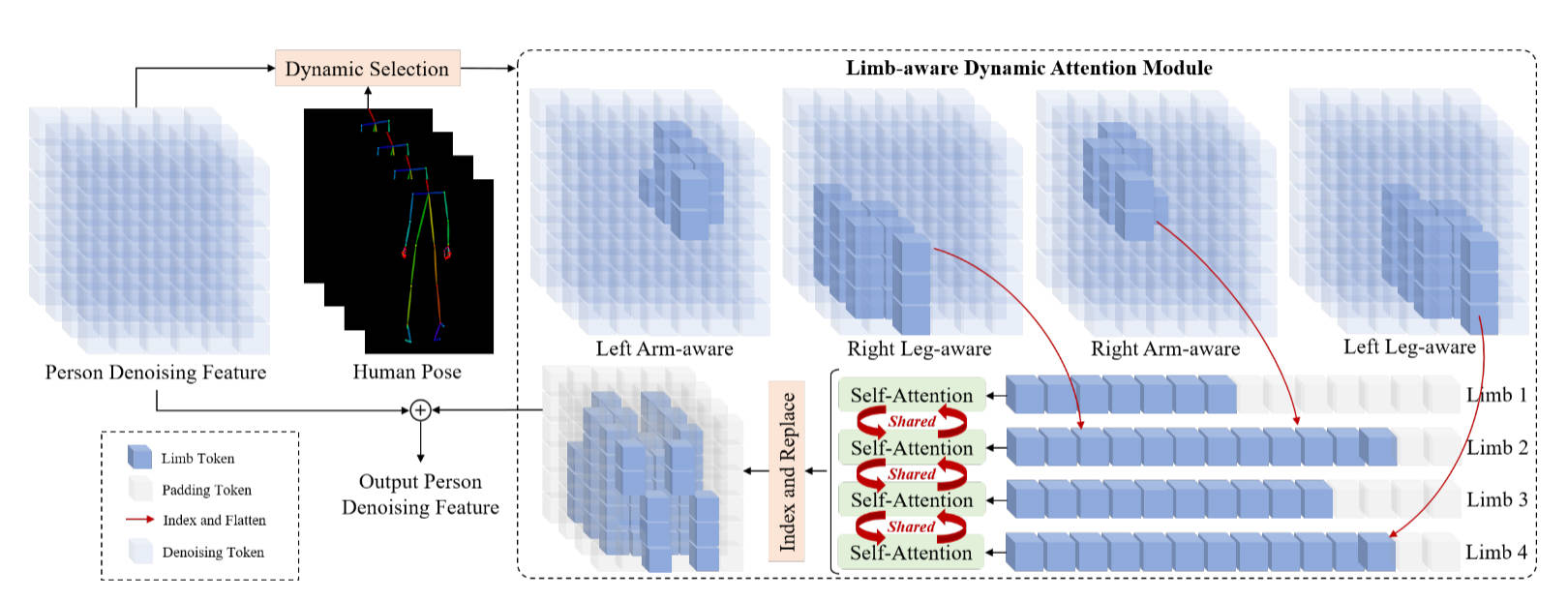
LDAM
如图2所示,本质上,作者希望网络能够关注视频中人物骨架运动过程的信息,作者通过骨架图和掩码找到人体骨骼在视频帧中所对应的具体的patch,然后作者将这些patch拼接在一起进行自注意力,注意力计算结果则直接加到原来的特征图中。算法1说明了详细的计算过程。

Multi-Stage Training
作者使用了预训练模型Opensora的模型权重。
- 在第一阶段作者只训练空间自注意力和交叉注意力层,任务是根据指定的服装图像来重建人物图像。
- 在第二阶段,作者训练ID-Encoder,训练目标与第一阶段相同,所有参数都进行训练。这一阶段LDAM没有加入到网络中。
- 在第三阶段,作者加入LDAM,并且只训练新加入的层。尽管这里没有提到,但第三阶段应该是也训练了时间自注意力层。