论文笔记|LatentSync:Taming Audio-Conditioned Latent Diffusion Models for Lip Sync with SyncNet Supervision
端到端音频条件潜在扩散模型(ldm)已被广泛应用于音频驱动的人像动画,证明了它们在生成逼真的高分辨率谈话视频方面的有效性。当前的口型同步(lip-sync)任务中口型同步的精度并不理想。本文指出了其根本性的问题:捷径学习(shortcut Learning problem)——模型经常学习视觉-视觉(visual-visual)的捷径而忽略关键的试听相关性(audio-visual correlation)。作者将SyncNet 集成到audio-conditioned LDMs中监督强制学习试听相关性。作者认为SyncNet对对口型精度的影响至关重要,进行了全面的实证分析来确定影响SyncNet收敛的关键因素。
本文主要贡献:
1)提出了LatentSync——第一个使用音频条件在高分辨率视频上实现端到端逼真口型同步的方法,提出了TREPA(Temporal Representation Alignment)增强视频的时间一致性.
2)发现了捷进学习问题,探索了将SyncNet 集成到audio-conditioned LDMs中监督强制学习试听相关性的解决方法。
3)进行了全面的实证研究分析SyncNet收敛的关键因素,提出了稳定收敛的StableSyncNet。
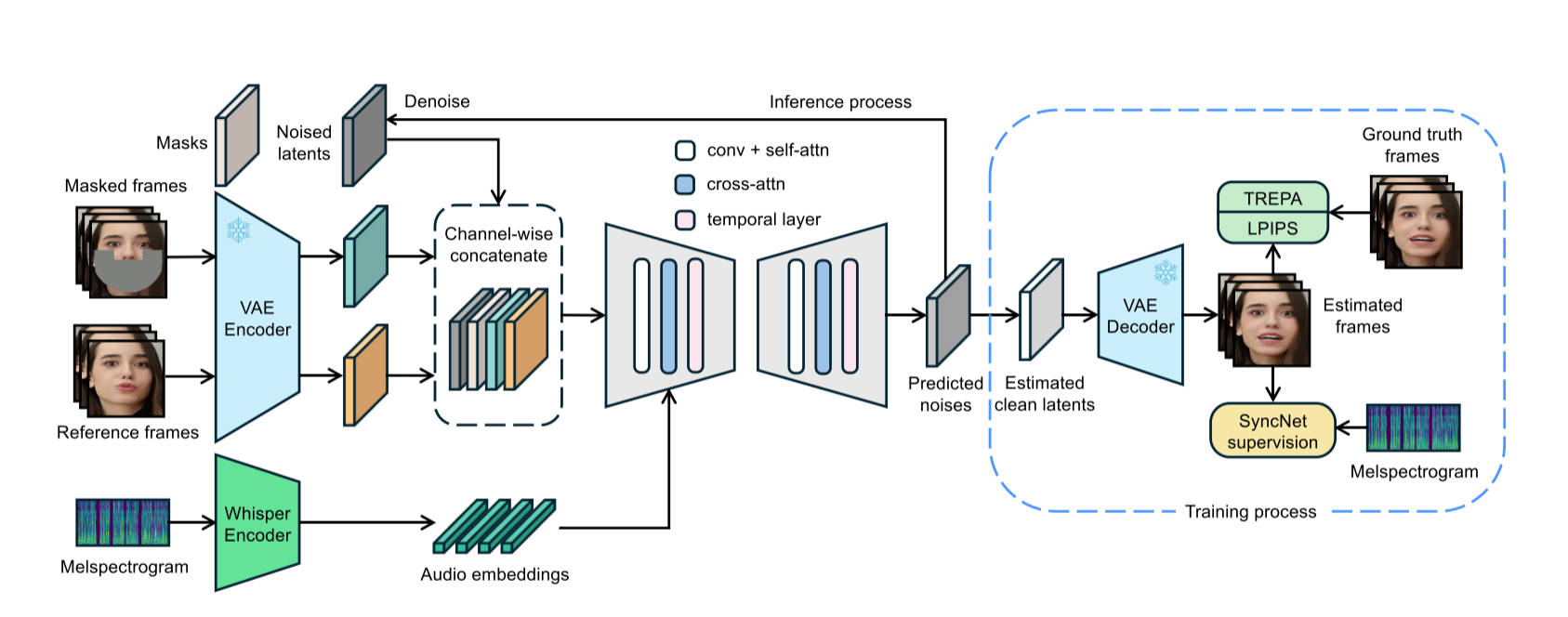
LatentSync Framework
LatentSync架构如图1所示。U-Net的大部分参数直接来自预训练模型SD 1.5。为了适配新任务,作者更换了输入层(conv_in),以及加入的交叉注意力层(cross-attn)采用了随机初始化。U-Net的输入包含13个通道,分别是mask, mask frames, reference frames以及Noised latents。
Audio layers
音频信息通过Whisper Encoder提取音频输入得到音频嵌入。通常口型动作收到当前音频以及周围音频的共同影响,作者将音频输入特征\(A^{(f)}\)定义为:\(A^{(f)} = {A^{(f)-m},...,A^{(f)},...A^{(f)+m}}\),其中f表示第f帧,m是一侧周围音频特征的数量。最后通过交叉注意力层合并到U-Net中。
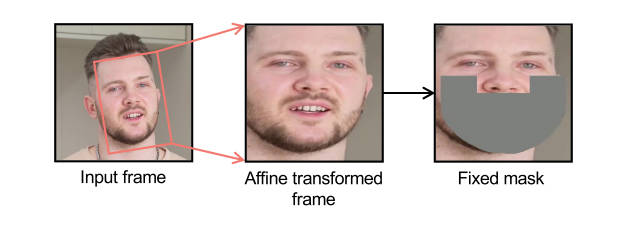
Affine transformation and fixed mask
作者使用仿射变换将人脸正面化,这有利于模型学习面部特征。同时在掩膜的选取上,作者采用覆盖几乎整个脸部的掩膜大小,希望最小化模型对捷径的依赖。
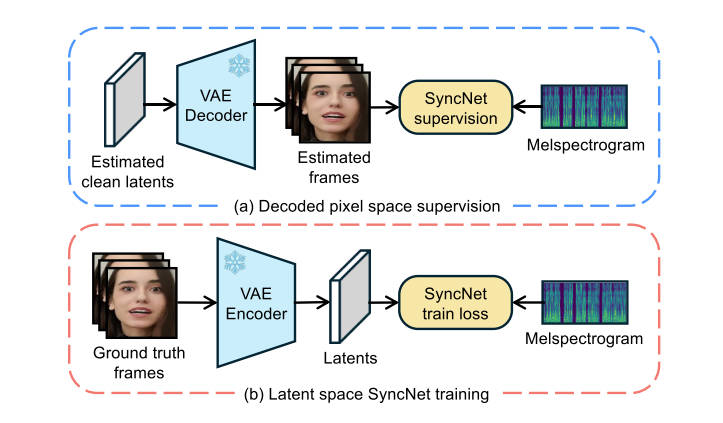
SyncNet supervision
SyncNet需要输入图像进行监督,而LDMs每次预测的是噪声,因此作者使用一步采样的结果作为图像输入:
\[ (\hat{z}_0) = (z_t - \sqrt{1-\bar{\alpha}}\epsilon_{\theta}(z_t)) / \sqrt{\bar{\alpha}_t} \]
作者讨论了SyncNet的两种空间设计,在后续的分析中证明了像素空间下具有更快的收敛速度。作者认为可能是在VAE编码过程中唇区信息丢失造成的。
两阶段训练策略
第一阶只训练U-Net学习从参考图像中提取视觉特征来修复图像,训练U-Net的全部参数,但不加入时间层:
\[ \mathcal{L}_{\text{simple}} = \mathbb{E}_{x, A, \epsilon \sim \mathcal{N}(0,1), t} \left[\left\lVert \epsilon - \epsilon_\theta \big( z_t, t, \tau_\theta(A) \big) \right\rVert_2^2 \right] \] 其中A是输入音频,\(\epsilon_{\theta}(z_t, t, \tau_{\theta(A)})\)是预测噪声,_{(A)}是音频特征提取器。
在训练的第二阶段,作者只训练时间层(temporal layer)和音频层(audio layer),而冻结 U-Net 的其他参数。假设有 16 帧解码后的视频片段 \(\mathcal{D}(\hat{z}_0)_{f:f+16}\) 以及对应的音频序列 \(a_{f:f+16}\),则 同步网络损失(SyncNet Loss) 定义为:
\[ \mathcal{L}_{\text{sync}} = \mathbb{E}_{x, a, \epsilon, t}\Big[\text{SyncNet}\big(\mathcal{D}(\hat{z}_0)_{f:f+16}, \, a_{f:f+16}\big)\Big] \] 其中 \(\mathcal{D}\) 表示 VAE 解码器。由于唇形同步(lipsync)任务需要生成细节区域(如嘴唇、牙齿、胡须等),为了提升生成图像的视觉质量,作者引入 LPIPS 损失:
\[ \mathcal{L}_{\text{lpips}} = \mathbb{E}_{x, \epsilon, t} \Big[\big\lVert \mathcal{V}_l(\mathcal{D}(\hat{z}_0)_f) - \mathcal{V}_l(x_f) \big\rVert_2^2 \Big] \] 其中 \(\mathcal{V}_l(\cdot)\) 表示从 预训练的 VGG 网络第 \(l\) 层提取的特征。
此外,为了增强时间一致性,还引入了提出的 TREPA 损失。 最终,第二阶段的总损失函数定义为:
\[ \mathcal{L}_{\text{total}} = \lambda_1 \mathcal{L}_{\text{simple}} + \lambda_2 \mathcal{L}_{\text{sync}} + \lambda_3 \mathcal{L}_{\text{lpips}} + \lambda_4 \mathcal{L}_{\text{trepa}} \]
TREPA(Temporal Representation Alignment)
考虑到一半的损失只能改善生成图像的内容质量而并不关注时序一致性,作者使用自监督视频模型VideoMAE-v2提取时序表征。设 \(\mathcal{T}\) 是一个自监督视频模型编码器(self-supervised video encoder),其输出为在 projection head 之前的嵌入表示。TREPA 损失定义为:
\[ \mathcal{L}_{\text{trepa}} = \mathbb{E}_{x, \epsilon, t} \Big[ \big\lVert \mathcal{T}(\mathcal{D}(\hat{z}_0)_{f:f+16}) - \mathcal{T}(x_{f:f+16}) \big\rVert_2^2 \Big] \] 其中,采用均方误差(MSE)来衡量生成视频片段与真实视频片段的时间表示(temporal representations)之间的差异。在计算 MSE 之前,特征表示会先经过 \(\ell_2\) 归一化。
SyncNet收敛性分析
这个部分探索了为什么SyncNet训练不收敛的原因,在我看来更像是寻找合适超参数的过程。作者最终确定batch size大小为1024,Embedding dimension为2048,number of frames为16。除此之外,作者介绍了SyncNet的结构和数据处理的一些过程,在仓库中可以看到详细的数据处理管道。
实验结果
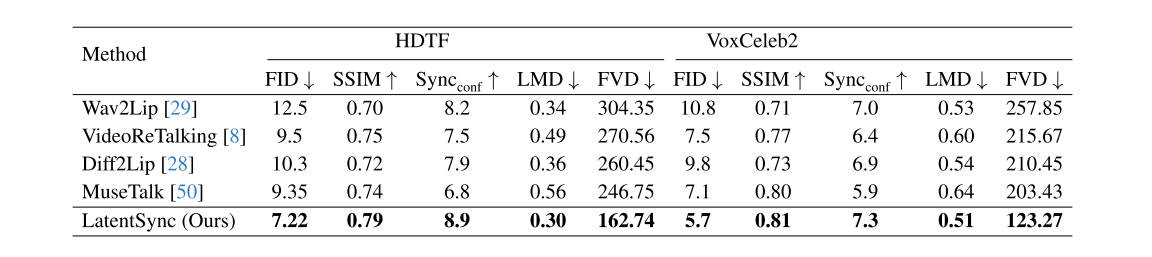
表1结果表明作者所提出的方法在HDTF数据集上取得的领先性能。更多的实验结果,实验设置细节和消融分析请阅读原文。