论文笔记|Representation Alignment for Generation:Training Diffusion Transformers Is Easier Than You Think
ICLR2025
扩散模型中的去噪过程中,在模型内部存在有意义的表征,尽管这些表征的质量仍然落后于通过最近的自监督学习方法学习到的表征。论文训练大规模扩散模型用于生成的一个主要瓶颈在于有效地学习这些表示。通过结合高质量的外部视觉表征,而不是仅仅依靠扩散模型来独立学习,训练可以变得更容易。作者通过引入一种称为表示对齐REPresentation
Alignment(REPA)的简单正则化来研究这一点,该正则化将去噪网络中噪声输入隐藏状态的投影与从外部预训练的视觉编码器获得的干净图像表示对齐。当应用于DiT和SiT时,REPA在训练效率和生成质量方面都有了显著的改进。REPA可以将SiT训练的速度提高17.5倍以上,与在不到400K步的情况下训练7M步的SiT-XL\2模型的性能(无cfg)相匹配。在最终生成质量方面,作者使用cfg和guidance
interval实现了FID=1.42的最先进结果。
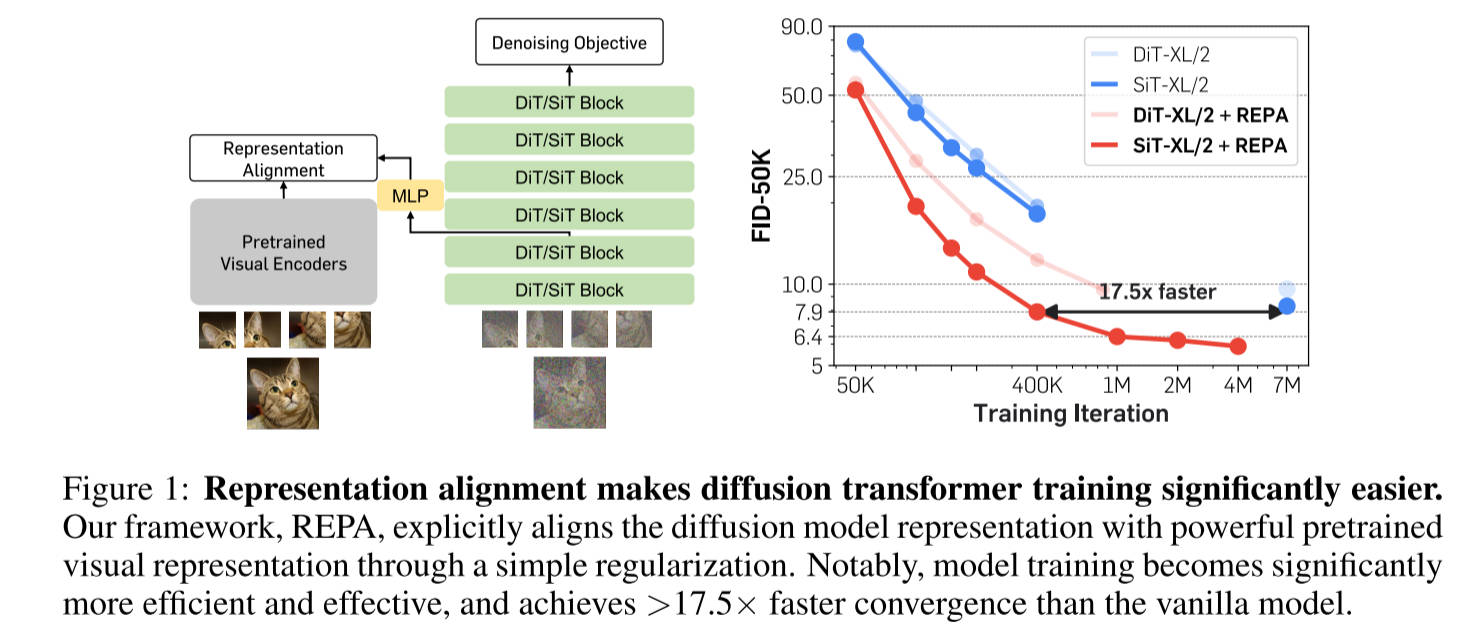
训练扩散模型的主要挑战源于需要学习高质量的内部表征。REPA表明:当生成式扩散模型得到来自另一个模型(例如自监督视觉编码器)的外部高质量表征的支持时,其性能可以得到大幅提升。论文使用 DINOv2 作为外部自监督视觉编码器提供表征对齐。
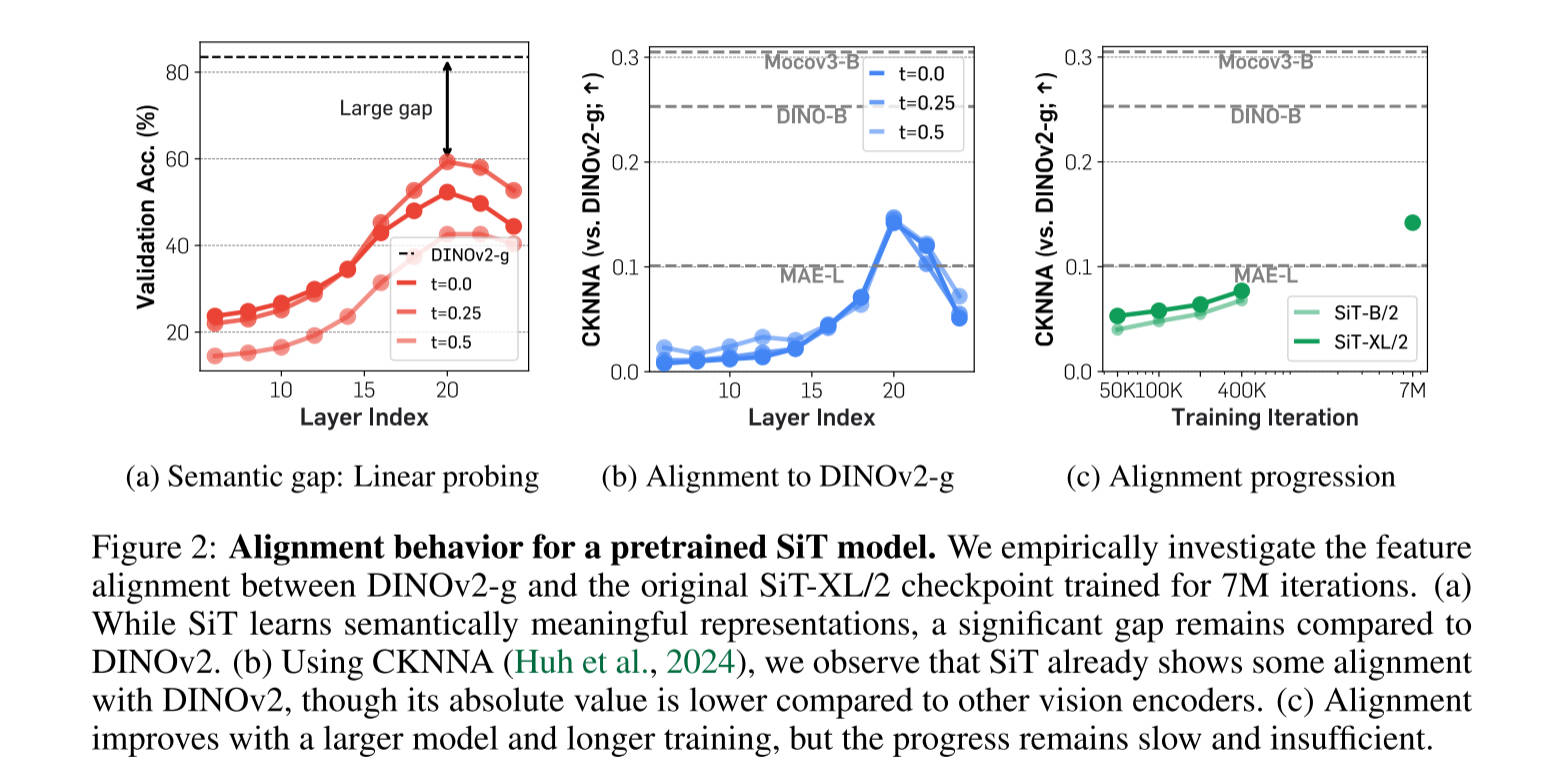
作者使用Linear Probing 和 CKNNA 来评估扩散模型的内部表征能力,图2a所示,作者观察到预训练扩散变压器的隐藏状态表示,在第20层实现了相当高的线性探测峰(t表示dropout ratio used in linear probing)。然而,它的性能仍然远远低于DINOv2,这表明两种表示之间存在很大的语义差距。此外,在达到这个峰值后,线性探测性能迅速下降,这表明扩散转换器必须从仅仅专注于学习语义丰富的表示转变为生成具有高频细节的图像。
在图2b中,作者使用CKNNA报告了SiT和DINOv2之间的代表性比对。特别是,SiT模型表示已经表现出比MAE更好的一致性。然而,绝对对齐得分仍然低于其他自监督学习方法(例如,MoCov3 vs. DINOv2)。这些结果表明,虽然扩散变压器表示与自监督视觉表示表现出一定的一致性,但一致性仍然很弱。
如图2c所示,作者通过更大的模型和扩展的训练观察到改进的对齐。然而,对齐仍然很低,并且没有达到其他自监督视觉编码器(例如,MoCov3和DINOv2)之间观察到的水平,即使经过大量的7M迭代训练。
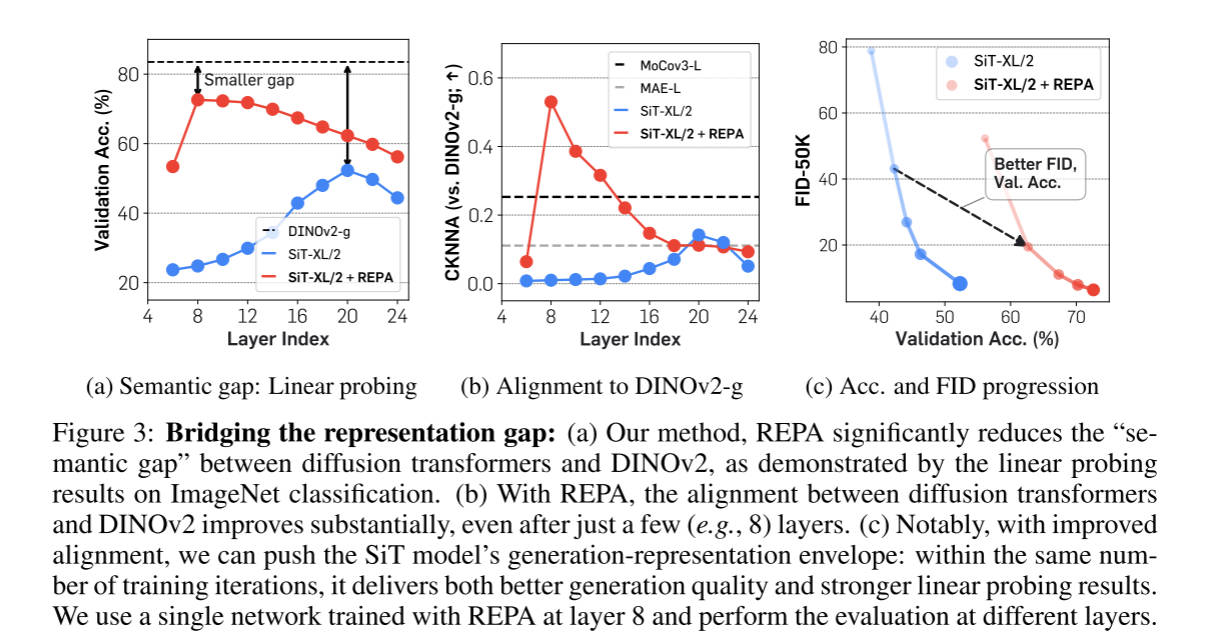
作者发现在SiT上,第8层施加REPA,Linear Probing 和 CKNNA 达到了峰值。
\[ \begin{equation} \mathcal{L}_{\text{REPA}}(\theta, \phi) := - \mathbb{E}_{\mathbf{x}_*, \epsilon, t} \left[ \frac{1}{N} \sum_{n=1}^{N} \operatorname{sim}(\mathbf{y}_*^{[n]}, \, h_\phi(h_t^{[n]})) \right] \end{equation} \]
REPA对齐损失如上,一张干净的图像\(x_*\),预训练编码器(如DINOV2)定义为\(f\),\(y_*=f(x_*) \in \mathcal{R}^{N×D}\),N和D分别是pathch的数量和embedding dimension of encoder output,\(h_t=f_{\theta}(z_t)\)是扩散模型的输出,并通过可学习映射层\(h_{\phi}(h_t)\)是一个MLP。
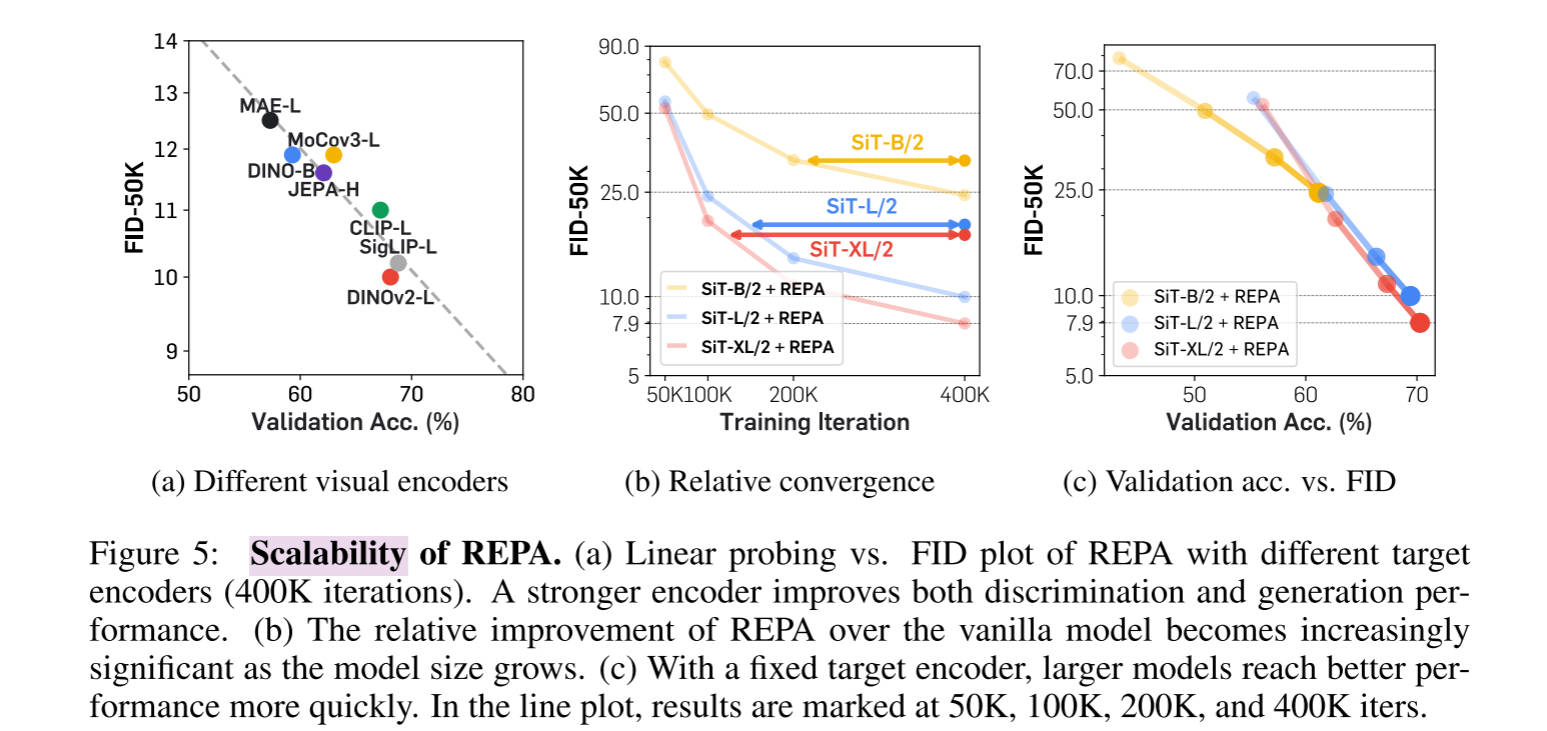
图5a分析了多种target encoder的效果,DINOV2实现最低FID的同时,预训练之后的DINOV2+SiT-L,在线性探测上实现了更高的线性探测准确率。